")
Master ETL Pipelines with our comprehensive guide. Learn about data extraction, transformation, loading processes, tools, and best practices for building efficient data integration systems.
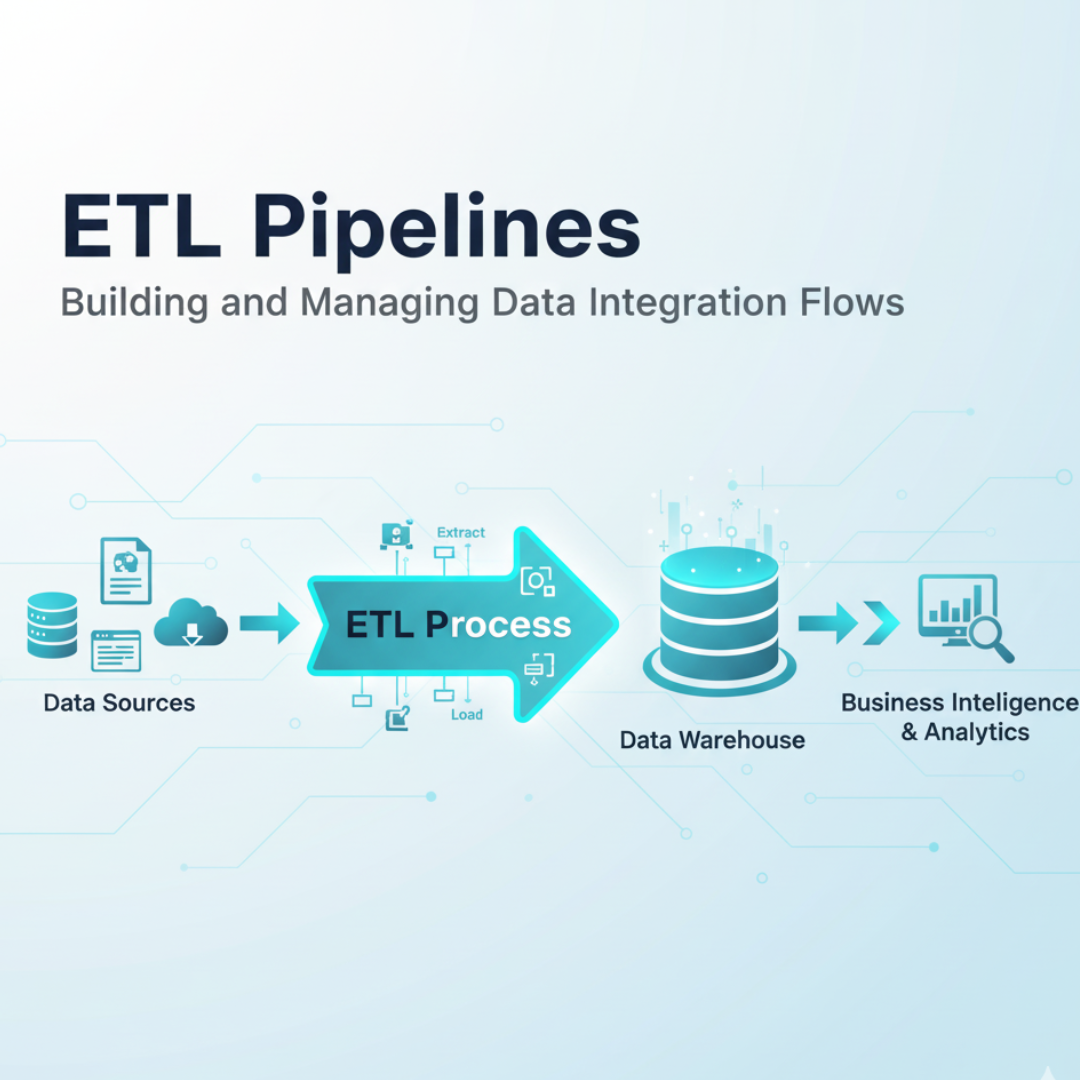
In today’s data-driven business environment, organizations face the critical challenge of transforming raw, disparate information into structured, actionable insights. At the heart of this transformation lie sophisticated ETL Pipelines that follow the time-tested methodology—Extract, Transform, Load. These systematic ETL Pipelines form the essential bridge between operational systems and analytical platforms, enabling businesses to harness the full potential of their data assets for strategic decision-making and operational excellence.
The evolution of ETL Pipelines has been remarkable, transitioning from traditional batch-oriented systems to modern, real-time streaming architectures. Contemporary ETL Pipelines leverage cloud technologies, advanced processing engines, and automated orchestration tools to handle the massive volumes and variety of information generated by today’s digital enterprises. This comprehensive guide explores the fundamental concepts, architectural patterns, implementation strategies, and emerging trends in building effective ETL Pipelines that power modern business intelligence and analytics initiatives.
Understanding the Data Integration Foundation
ETL Pipelines form the core of information management strategies across organizations of all sizes and industries. These systematic processes involve extracting information from various source systems, transforming it into consistent formats, and loading it into target destinations like data warehouses or data lakes. The design and implementation of ETL Pipelines require careful consideration of data quality, processing efficiency, and business requirements to ensure reliable data delivery for analytical and operational purposes.
The fundamental architecture of ETL Pipelines follows a sequential pattern where each stage serves a distinct purpose. Extraction involves pulling data from source systems, which can include relational databases, SaaS applications, IoT devices, or file storage systems. Transformation encompasses cleaning, validating, and restructuring the extracted information to meet business rules and quality standards. Loading focuses on efficiently moving the processed data into target systems while maintaining data integrity and consistency. Modern ETL Pipelines often incorporate sophisticated error handling, monitoring, and recovery mechanisms to ensure reliable operation across diverse business scenarios.
Key Components of Modern ETL Pipelines
Contemporary ETL Pipelines consist of several interconnected components that work together to process information efficiently. Understanding these elements is essential for designing robust ETL Pipelines that can scale with evolving business needs and technological capabilities.
Extraction Layer: Source System Integration
The extraction phase in ETL Pipelines involves connecting to various data sources and retrieving information for subsequent processing. Modern ETL Pipelines must handle diverse source types including traditional relational databases like MySQL, PostgreSQL, and Oracle; cloud-based SaaS applications such as Salesforce, Marketo, and HubSpot; streaming data sources including Kafka, Kinesis, and Event Hubs; file-based sources in formats like CSV, JSON, Parquet, and XML; and various API endpoints and web services.
Effective ETL Pipelines implement intelligent extraction strategies that minimize impact on source systems while ensuring data completeness. Change Data Capture techniques, incremental extraction methods, and parallel processing capabilities are essential features of modern extraction layers in ETL Pipelines. These approaches help maintain system performance while ensuring that data remains current and accurately reflects business operations across all integrated systems.
Transformation Engine: Data Processing Logic
The transformation component represents the computational core of ETL Pipelines where raw data is converted into analysis-ready formats. This critical stage typically includes comprehensive data validation and quality checks, schema transformation and mapping operations, implementation of complex business rules, data enrichment and augmentation processes, aggregation and summarization for reporting needs, and careful handling of personally identifiable information through masking and anonymization techniques.
Modern ETL Pipelines leverage distributed processing technologies like Apache Spark, Flink, or cloud-native services to handle large-scale transformation workloads efficiently. The transformation logic in contemporary ETL Pipelines often incorporates machine learning algorithms for advanced data cleansing, pattern recognition, and anomaly detection. These advanced capabilities enable organizations to maintain high data quality standards while adapting to evolving business requirements and data characteristics.
Loading Mechanisms: Target System Integration
The loading phase in ETL Pipelines focuses on efficiently moving transformed information into destination systems. This crucial component must handle bulk loading operations for initial datasets, incremental updates for changing information, conflict resolution and duplicate handling mechanisms, data type conversion and compatibility management, and performance optimization specific to target system characteristics.
Sophisticated ETL Pipelines implement smart loading strategies that consider the unique characteristics of target environments, whether they’re traditional data warehouses, cloud data platforms, or real-time analytical databases. Modern ETL Pipelines often feature parallel loading capabilities, comprehensive transaction management, and robust rollback mechanisms to ensure data consistency across all integrated systems. These features become particularly important when dealing with large volumes of data or when maintaining near-real-time synchronization between operational and analytical systems.
Architectural Patterns for ETL Pipelines
The design of ETL Pipelines has evolved significantly, with several architectural patterns emerging to address different business requirements and technical constraints. Understanding these patterns helps organizations select the most appropriate approach for their specific use cases and operational environments.
")
Traditional Batch ETL Pipelines
Batch-oriented ETL Pipelines process information in scheduled intervals, typically handling large volumes of data during off-peak hours. These ETL Pipelines follow a predictable execution pattern that includes data extraction from source systems at scheduled intervals, batch processing of accumulated information, bulk loading into target environments, and comprehensive error handling and logging mechanisms.
Traditional batch ETL Pipelines remain popular for scenarios where real-time data access isn’t critical, such as nightly reporting, historical analysis, and regulatory compliance reporting. These ETL Pipelines benefit from mature tooling ecosystems, predictable resource requirements, and well-understood operational patterns. Many organizations continue to rely on batch processing for foundational data integration needs while gradually incorporating more real-time capabilities for specific use cases.
Streaming ETL Pipelines
Modern business requirements often demand real-time data access and processing, leading to the development of streaming ETL Pipelines. These advanced architectures process information continuously as it arrives, enabling real-time analytics and dashboard updates, immediate fraud detection and prevention, instant personalization and recommendation engines, and live operational monitoring and alerting systems.
Streaming ETL Pipelines leverage technologies like Apache Kafka, Amazon Kinesis, or Google Pub/Sub to handle continuous data flows. These ETL Pipelines require sophisticated state management, windowing operations, and exactly-once processing semantics to ensure data accuracy and consistency. The implementation of streaming solutions typically involves more complex operational considerations but delivers significant business value through timely insights and rapid response capabilities.
Cloud-Native ETL Pipelines
The migration to cloud platforms has catalyzed the development of cloud-native ETL Pipelines that leverage managed services and serverless architectures. These modern ETL Pipelines offer automatic scaling based on workload demands, pay-per-use pricing models, built-in monitoring and management capabilities, and native integration with cloud data services and storage solutions.
Cloud-native ETL Pipelines typically combine services like AWS Glue, Azure Data Factory, or Google Dataflow with serverless computing and managed storage. These ETL Pipelines reduce operational overhead while providing enterprise-grade reliability and performance characteristics. The cloud-native approach has made sophisticated data integration capabilities accessible to organizations of all sizes, democratizing access to advanced data processing technologies.
Implementation Best Practices for ETL Pipelines
Building successful ETL Pipelines requires adherence to established best practices that ensure reliability, maintainability, and performance. These guidelines help organizations avoid common pitfalls and maximize the value of their data integration investments while maintaining operational excellence.
Data Quality and Validation Framework
Robust ETL Pipelines incorporate comprehensive data quality checks throughout the processing workflow. Implementation should include schema validation and data type checking, mandatory field validation and completeness verification, data range and format validation, cross-field validation and business rule enforcement, and duplicate detection and handling mechanisms.
Modern ETL Pipelines often implement progressive validation strategies, with basic checks during extraction and more sophisticated validation during transformation phases. Effective ETL Pipelines maintain detailed quality metrics and provide clear error reporting for data stewardship activities. These capabilities ensure that data quality issues are identified early and addressed systematically, preventing problematic data from propagating through the organization’s analytical ecosystems.
Error Handling and Recovery Strategies
Reliable ETL Pipelines implement sophisticated error handling mechanisms that ensure processing continuity and data integrity. Key considerations include automatic retry mechanisms for transient failures, dead letter queues for problematic records, comprehensive logging and alerting systems, data lineage tracking and impact analysis capabilities, and automated recovery and restart functionalities.
Well-designed ETL Pipelines maintain processing state information, enabling graceful recovery from failures without data loss or corruption. These ETL Pipelines typically include manual intervention capabilities for handling exceptional situations that require human judgment or business context. The implementation of robust error handling becomes increasingly important as organizations scale their data operations and depend more heavily on data-driven decision processes.
Performance Optimization Techniques
High-performance ETL Pipelines employ various optimization techniques to handle large data volumes efficiently. Common strategies include parallel processing and distributed computing approaches, incremental processing for changing data scenarios, data partitioning and intelligent scheduling mechanisms, memory management and resource optimization, and query optimization and indexing strategies.
Modern ETL Pipelines leverage columnar storage formats, compression techniques, and predicate pushdown to minimize data movement and improve processing efficiency. Performance monitoring and capacity planning are essential components of maintaining optimized ETL Pipelines, particularly as data volumes grow and business requirements evolve. Regular performance assessment and tuning ensure that data integration processes continue to meet service level agreements and user expectations.
Tools and Technology Landscape for ETL Pipelines
The ecosystem of tools for building and managing ETL Pipelines has expanded significantly, offering solutions for various technical requirements and skill levels. Understanding the available options helps organizations select the most appropriate technology stack for their specific needs and constraints.
Traditional ETL Platforms
Established data integration tools provide comprehensive environments for designing and managing ETL Pipelines. These offerings typically feature visual development interfaces, pre-built connectors and transformations, enterprise-grade security and governance capabilities, advanced scheduling and monitoring functionalities, and cross-platform deployment options.
Popular traditional tools include Informatica PowerCenter, IBM DataStage, and SAS Data Integration Studio. These solutions remain relevant for organizations with complex integration requirements and established operational practices. While sometimes perceived as less agile than modern alternatives, these platforms offer proven reliability and extensive feature sets that continue to serve enterprise needs effectively.
Open-Source ETL Frameworks
Open-source technologies have dramatically transformed the landscape of ETL Pipelines, offering flexibility and cost-effectiveness. Key frameworks include Apache Spark for large-scale data processing, Apache Airflow for workflow orchestration, Apache NiFi for data flow management, Talend Open Studio for visual development, and Pentaho Data Integration for comprehensive ETL capabilities.
Open-source ETL Pipelines benefit from active community development, extensive customization options, and avoidance of vendor lock-in concerns. However, they often require significant technical expertise and operational investment. Organizations choosing open-source approaches must carefully consider their internal capabilities and long-term maintenance strategies to ensure successful implementation and operation.
Cloud-Native ETL Services
Cloud providers offer managed services that simplify the implementation of ETL Pipelines. These services provide serverless execution and automatic scaling, native integration with cloud storage and databases, built-in monitoring and management consoles, pay-per-use pricing models, and regular feature updates and enhancements.
Leading cloud-native services include AWS Glue, Azure Data Factory, and Google Cloud Dataflow. These platforms significantly reduce the operational burden of maintaining ETL Pipelines while providing enterprise-grade reliability and security characteristics. The choice between cloud-native services often depends on an organization’s existing cloud investments, technical preferences, and specific integration requirements.
Data Governance in ETL Pipelines
Effective data governance is crucial for maintaining trust in ETL Pipelines and ensuring compliance with regulatory requirements. Modern approaches incorporate governance capabilities throughout the data lifecycle, from initial acquisition through final consumption.
Metadata Management Framework
Comprehensive ETL Pipelines maintain detailed metadata that describes data origins, transformations, and usage patterns. Key aspects include data lineage tracking from source to consumption, business glossary and data dictionary management, data classification and sensitivity tagging, processing history and change tracking, and impact analysis for schema modifications.
Advanced ETL Pipelines integrate with enterprise metadata repositories and data catalog systems to provide unified visibility across the organization. This metadata foundation enables self-service analytics and improves data discovery capabilities. Effective metadata management ensures that data consumers understand the context, quality, and appropriate usage of available data assets, fostering greater trust and utilization.
Security and Compliance Considerations
Secure ETL Pipelines implement robust security measures that protect sensitive information throughout processing. Essential security features include encryption for data in transit and at rest, access control and authentication mechanisms, data masking and anonymization capabilities, audit logging and compliance reporting, and privacy regulation compliance for standards like GDPR and CCPA.
Modern ETL Pipelines incorporate security-by-design principles, with built-in capabilities for handling personally identifiable information and enforcing data protection policies across all processing stages. These security measures become increasingly important as organizations handle more sensitive data and face evolving regulatory requirements across different jurisdictions and industries.
Monitoring and Operational Excellence
Operational excellence requires comprehensive monitoring and proactive maintenance of ETL Pipelines. Effective monitoring strategies encompass multiple dimensions of system health, performance, and data quality to ensure reliable operation and continuous improvement.
")
Performance Monitoring Framework
Continuous performance monitoring helps identify bottlenecks and optimization opportunities in ETL Pipelines. Key metrics include data processing throughput and latency measurements, resource utilization and cost efficiency indicators, processing success rates and error frequencies, data quality metrics and validation results, and end-to-end pipeline execution times.
Modern ETL Pipelines leverage automated monitoring solutions that provide real-time alerts and historical trend analysis. These systems enable proactive capacity planning and performance tuning, helping organizations maintain service level agreements and optimize resource utilization. Effective performance monitoring provides the insights needed to balance cost, performance, and reliability considerations across the data integration landscape.
Data Quality Assessment
Ongoing data quality assessment ensures that ETL Pipelines continue to deliver accurate and reliable information. Monitoring activities include automated data profiling and statistical analysis, anomaly detection and outlier identification, data freshness and completeness verification, business rule validation and compliance checking, and data reconciliation between source and target systems.
Sophisticated ETL Pipelines incorporate machine learning algorithms that automatically detect data quality issues and recommend corrective actions. These advanced capabilities provide data stewards with comprehensive visibility into data health and enable more proactive quality management. Regular data quality assessment helps maintain trust in analytical outputs and supports confident decision-making across the organization.
Advanced ETL Pipeline Patterns
As data requirements evolve, advanced patterns for ETL Pipelines have emerged to address complex integration scenarios and specialized use cases. These approaches represent the cutting edge of data integration practice and offer solutions for particularly challenging business and technical requirements.
")
Data Mesh and Distributed ETL Pipelines
The data mesh architecture promotes domain-oriented ownership of data products, influencing the design of modern ETL Pipelines. This innovative approach features federated governance and domain autonomy, self-service data infrastructure capabilities, product-thinking for data assets, domain-oriented data processing, and standardized interfaces and contracts between domains.
Data mesh emphasize interoperability and reusability while maintaining domain-specific customization. These approaches facilitate decentralized data management while ensuring organizational consistency and compliance. The implementation of data mesh principles represents a significant organizational and technical shift but offers compelling benefits for large, complex enterprises with diverse data needs.
Machine Learning-Enhanced ETL Pipelines
Artificial intelligence and machine learning are transforming traditional into intelligent information processing systems. ML-enhanced incorporate automated data classification and tagging capabilities, intelligent anomaly detection and correction mechanisms, predictive data quality assessment, adaptive schema mapping and evolution, and natural language processing for unstructured data interpretation.
These advanced reduce manual intervention while improving processing accuracy and efficiency. Machine learning technologies enable to adapt to changing data patterns and business requirements more effectively. The integration of AI and ML capabilities represents a significant advancement in making data integration processes more intelligent, adaptive, and efficient.
Future Trends
The evolution continues as new technologies and approaches emerge. Several significant trends are shaping the future direction of data processing systems and their role in organizational information management.
Real-Time Processing Dominance
The demand for real-time insights is driving the adoption of streaming across industries. Future developments include unified batch and streaming processing capabilities, complex event processing and pattern detection, real-time data quality and validation, streaming analytics and immediate insights generation, and event-driven architecture integration.
Modern ETL Pipelines will increasingly prioritize low-latency processing while maintaining the reliability and consistency of traditional batch systems. This evolution reflects the growing business need for timely information and the ability to respond quickly to changing conditions and opportunities in increasingly dynamic market environments.
AI-Driven Automation Advancements
Artificial intelligence is revolutionizing designed, implemented, and operated. Emerging capabilities include automated pipeline generation from natural language descriptions, intelligent error resolution and self-healing mechanisms, predictive performance optimization, automated data mapping and transformation, and cognitive data quality management.
AI-enhanced will significantly reduce development time and operational overhead while improving reliability and performance characteristics. These advancements promise to make sophisticated data integration capabilities more accessible to organizations with limited technical resources while enabling more complex and valuable data processing scenarios.
Cloud-Native Evolution
The migration to cloud platforms continues to influence architecture and implementation approaches. Future trends include complete serverless execution models, automated cost optimization and resource management, native integration with cloud AI services, cross-cloud and hybrid deployment options, and containerized and microservices-based architectures.
These developments will make more accessible, cost-effective, and scalable for organizations of all sizes. The continued evolution of cloud-native approaches represents a fundamental shift in how organizations build, deploy, and operate data integration solutions, with significant implications for cost, flexibility, and innovation velocity.
Conclusion
ETL Pipelines remain fundamental to successful information management and analytics initiatives in the modern enterprise. As organizations increasingly rely on data-driven decision-making, the role of robust, scalable, and reliable becomes ever more critical. The evolution from traditional batch processing to modern, real-time, and AI-enhanced reflects the growing sophistication of data integration requirements across industries and the increasing strategic importance of data assets.
Implementing effective requires careful consideration of architectural patterns, technology selection, and operational practices. Organizations must balance performance requirements with maintainability, cost considerations with functionality, and innovation with stability. The future of points toward greater automation, intelligence, and real-time capabilities, enabling organizations to derive maximum value from their information assets while managing complexity and cost effectively.
As data volumes continue to grow and business requirements evolve, sophisticated will remain essential components of the information infrastructure landscape. Organizations that invest in building and maintaining advanced will be better positioned to leverage their information assets for competitive advantage, operational efficiency, and business innovation. The journey toward data excellence begins with well-designed that transform raw information into actionable intelligence, enabling organizations to navigate increasingly complex business environments and capitalize on emerging opportunities in the digital economy.