")
Master Reinforcement Learning with our complete guide. Explore key algorithms like Q-Learning and PPO, real-world applications, and the future of AI’s trial-and-error learning paradigm. Your definitive resource for understanding Reinforcement Learning.
In the vast landscape of artificial intelligence, if Supervised Learning is the student who learns from a labeled textbook and Unsupervised Learning is the explorer charting unknown territories, then Reinforcement Learning is the pioneer learning to navigate the world through trial and error, guided by rewards and punishments. It is the computational theory of learning from interaction, and it powers some of the most impressive achievements in modern AI, from mastering complex games like Go and Dota 2 to training robotic hands to perform dexterous manipulation. This comprehensive guide will serve as your deep dive into the world of Reinforcement Learning, unpacking its core principles, key algorithms, real-world applications, and the exciting future it promises.
What is Reinforcement Learning? The Trial-and-Error Paradigm
At its core, Reinforcement Learning is a machine learning paradigm where an intelligent agent learns to make decisions by performing actions in an environment and receiving feedback in the form of rewards or penalties. Unlike supervised learning, there is no dataset of correct answers. Instead, the agent must discover which actions yield the most reward through exploration and experience. The ultimate goal in any Reinforcement Learning setup is to learn an optimal policy—a strategy that tells the agent what action to take in any given situation to maximize its cumulative long-term reward.
The best analogy for Reinforcement Learning is training a dog. You don’t give the dog a manual on how to sit; you give a command, and if the dog sits, you provide a treat (a positive reward). If it doesn’t, you might withhold the treat or give a gentle correction. Over time, the dog associates the action of sitting with a positive outcome and learns to repeat it. This fundamental process of learning from consequences is the essence of Reinforcement Learning.
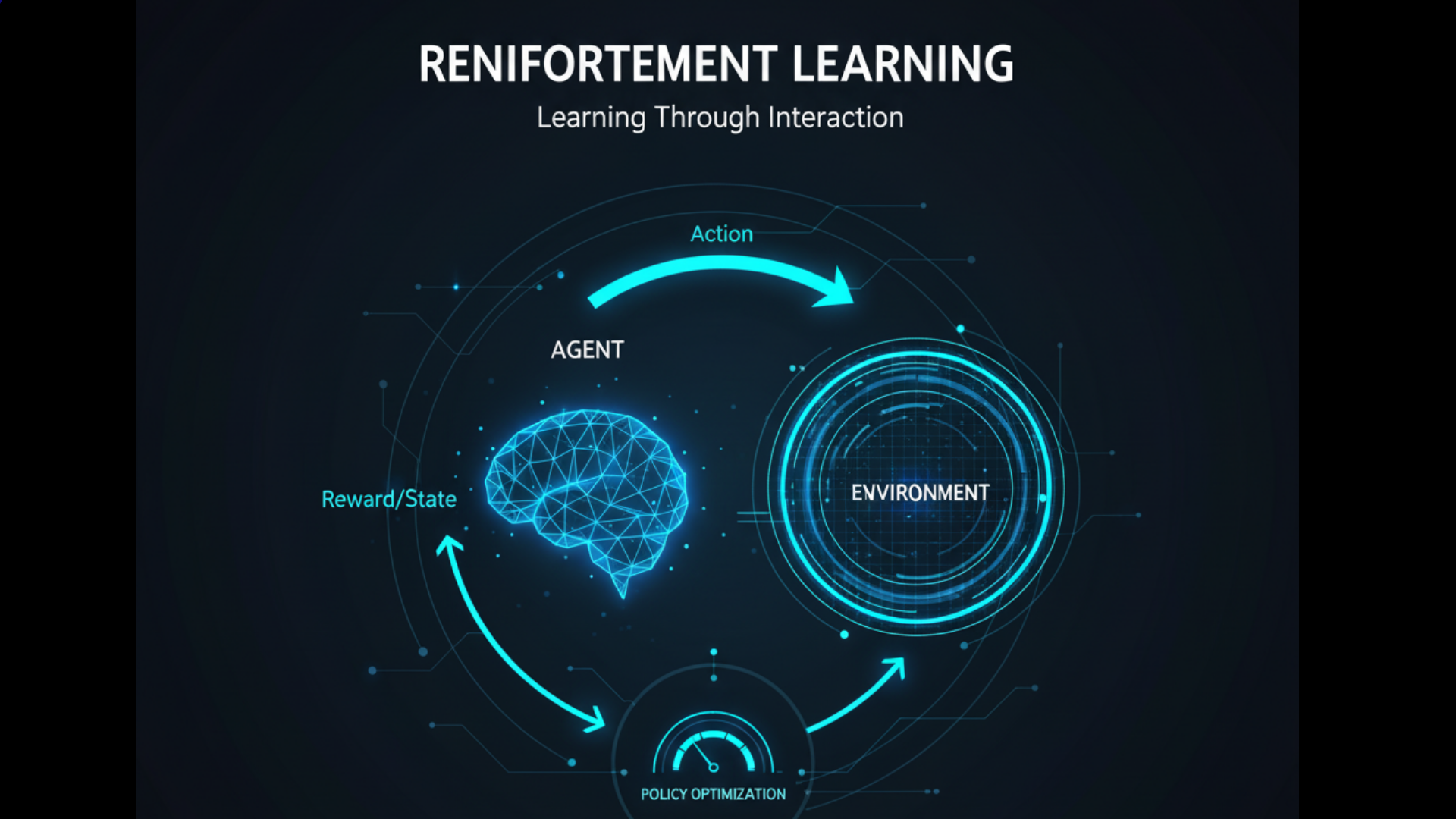
The Fundamental Framework: Key Components of a Reinforcement Learning System
Every Reinforcement Learning problem can be framed by a few essential components that form the Agent-Environment loop.
- Agent: The learner and decision-maker (e.g., an AI playing a game, a robotic controller).
- Environment: The world through which the agent moves and which it interacts with (e.g., the chessboard, the physical world, a stock market simulation).
- State (s): A situation or a configuration of the environment at a specific time. The state is the agent’s perception of the environment.
- Action (a): A move or decision made by the agent that changes the state of the environment.
- Reward (r): A scalar feedback signal from the environment indicating the immediate benefit of taking an action in a given state. The reward is the primary guiding force in Reinforcement Learning.
- Policy (π): The agent’s strategy or behavior function. It is a mapping from states to actions. Essentially, it is the “brain” of the agent, defining what it will do in any situation.
- Value Function (V(s)): This predicts the expected cumulative long-term reward starting from a given state, following a specific policy. While the reward is immediate, the value is long-term. Distinguishing between immediate reward and long-term value is a critical concept in Reinforcement Learning.
- Model (Optional): The agent’s representation of how the environment works. It allows the agent to predict the next state and reward given a current state and action. Not all Reinforcement Learning methods use a model.
The interaction loop is continuous: The agent observes the state s_t, takes an action a_t, receives a reward r_{t+1}, and finds itself in a new state s_{t+1}. This cycle repeats as the agent learns.
The Core Challenge: The Exploration vs. Exploitation Dilemma
A fundamental challenge that every Reinforcement Learning agent must face is the trade-off between exploration and exploitation.
")
- Exploitation: Leveraging current knowledge to choose actions that have yielded high rewards in the past. This is the “greedy” approach—sticking to what works.
- Exploration: Trying out new actions that the agent has not taken before, to potentially discover strategies that lead to even higher rewards in the long run.
Imagine a gambler at a row of slot machines. Exploitation would be playing the machine that has paid out the most so far. Exploration would be trying a different machine that might have an even higher payout. A pure exploitation strategy might lead to getting stuck in a suboptimal routine, while pure exploration might mean never capitalizing on a good find.
A successful Reinforcement Learning algorithm must balance these two competing demands to find the optimal policy. Strategies like ε-greedy (where the agent usually exploits but randomly explores with a small probability ε) are commonly used to address this dilemma in Reinforcement Learning.
A Journey Through Key Reinforcement Learning Algorithms
The field of Reinforcement Learning has evolved from simple, tabular methods to complex, deep learning-based systems. Understanding this progression is key to mastering the subject.
1. Value-Based Methods: Learning What’s Good
These methods focus on learning the value of being in a state, or the value of taking an action in a state. The policy is then derived from the value function (e.g., always move to the state with the highest value).
- Q-Learning: This is a foundational and hugely influential algorithm in Reinforcement Learning. It learns a Q-function,
Q(s, a), which represents the quality of taking actionain states. The “quality” is the expected cumulative future reward. The algorithm updates its Q-values iteratively using the Bellman equation. Its most significant feature is that it is an off-policy algorithm, meaning it can learn the optimal policy without following it, by learning from experiences generated by a different, exploratory policy. - SARSA (State-Action-Reward-State-Action): Similar to Q-Learning, SARSA is an on-policy algorithm, meaning it learns the value of the policy it is currently following. It tends to be more conservative than Q-Learning because it incorporates the action it will actually take next into its update.
2. Policy-Based Methods: Learning What to Do
Instead of learning values and deriving a policy, these methods directly learn the policy function π(a|s) itself. They are particularly useful when the action space is continuous or stochastic.
- REINFORCE: A classic policy gradient algorithm. It operates by running a complete episode of interaction with the environment, then adjusting the policy parameters in the direction that increases the probability of actions that led to high rewards. It is a Monte Carlo method, meaning it requires a full episode to complete before updating.
3. Model-Based Methods: Learning the World’s Dynamics
These algorithms learn a model of the environment—its transition dynamics (how states change) and reward function. The agent can then use this model to plan, by simulating future states and actions internally before taking real actions. While potentially very data-efficient, model-based Reinforcement Learning can be complex because any inaccuracies in the learned model can compound and lead to poor performance.
4. The Revolution: Deep Reinforcement Learning (DRL)
The breakthrough that propelled Reinforcement Learning into the mainstream was its combination with deep learning. Deep Reinforcement Learning uses neural networks to represent the value function, policy, or model, enabling agents to tackle problems with high-dimensional state spaces, like pixels from a video game screen.
- Deep Q-Networks (DQN): A landmark achievement from DeepMind. DQN used a deep neural network to approximate the Q-function in complex environments like Atari games. It introduced key techniques to stabilize training, such as experience replay (storing and randomly sampling past experiences to break correlations) and target networks (using a separate, slowly-updated network to calculate target Q-values).
- Actor-Critic Methods: This powerful hybrid architecture combines the best of both value-based and policy-based methods. The system has two components:
- The Actor: A policy network that decides which action to take.
- The Critic: A value network that evaluates the action taken by the actor.
The critic provides a feedback signal to the actor, telling it whether its action was better or worse than expected, allowing the actor to update its policy accordingly. Advanced algorithms like Proximal Policy Optimization (PPO) and Soft Actor-Critic (SAC) are state-of-the-art Actor-Critic methods that have achieved remarkable success.
The Reinforcement Learning Workflow: From Simulation to Solution
Building and training a Reinforcement Learning agent is an iterative process that typically follows these steps:
- Problem Formulation: Define the goal. What should the agent achieve? This is the most critical step in setting up a Reinforcement Learning task.
- Environment Design: Create or select a simulation or real-world environment. The environment must provide states, accept actions, and return rewards. For complex real-world tasks, simulation is almost always the starting point due to safety and data-efficiency concerns.
- State, Action, and Reward Engineering: This is a crucial design phase.
- State Representation: What information does the agent need to see? This could be raw sensor data (pixels) or a structured representation (object positions).
- Action Space: Is the action discrete (left, right, jump) or continuous (torque applied to a joint)?
- Reward Shaping: Designing the reward function is an art. The reward must correctly guide the agent toward the ultimate goal. A poorly shaped reward can lead to “reward hacking,” where the agent finds a loophole to maximize reward without actually achieving the desired outcome.
- Agent and Algorithm Selection: Choose the appropriate Reinforcement Learning algorithm based on the problem properties (e.g., DQN for discrete actions, PPO/SAC for continuous control).
- Training Loop: This is the core computational phase. The agent interacts with the environment for millions of steps, continuously updating its policy based on the experiences collected. This process is often computationally intensive and requires significant resources.
- Evaluation and Deployment: The trained agent’s policy is evaluated on its performance. Once it meets the desired criteria, it can be deployed in the real world, though often with ongoing monitoring and potential fine-tuning.
Real-World Applications of Reinforcement Learning
While often demonstrated in games, the practical applications of Reinforcement Learning are rapidly expanding across industries.
- Robotics: Reinforcement Learning is used to teach robots complex skills like walking, grasping, and manipulation directly from raw sensor inputs, reducing the need for manual programming.
- Resource Management: It is used in data centers to optimize cooling and power usage, and in logistics to manage inventory and supply chains.
- Finance: Developing trading strategies that can adapt to changing market conditions is a key application of Reinforcement Learning in algorithmic trading.
- Autonomous Systems: While self-driving cars use a mix of techniques, Reinforcement Learning is applied to specific sub-problems like path planning and strategic decision-making on the road.
- Healthcare: It is being explored for creating personalized treatment plans and for optimizing patient dosing schedules in dynamic environments.
- Recommendation Systems: Companies like Netflix and YouTube can use Reinforcement Learning to optimize long-term user engagement, rather than just predicting the next click.
Challenges and Limitations in Reinforcement Learning
Despite its promise, Reinforcement Learning faces significant hurdles that limit its widespread adoption.
- Sample Inefficiency: Most Reinforcement Learning algorithms require a massive number of interactions with the environment to learn, which is often impractical, expensive, or dangerous in the real world.
- The Simulation-to-Reality Gap (Sim2Real): Agents trained perfectly in simulation often fail when deployed in the real world due to unmodeled physics, sensor noise, and other complexities. Transferring learned policies is a major research challenge.
- Reward Function Design: As mentioned, designing a reward function that perfectly captures the intended goal is difficult. A slight misspecification can lead to unintended and often bizarre agent behaviors.
- Safety and Reliability: For real-world applications like autonomous driving or healthcare, an agent’s exploratory actions could have catastrophic consequences. Ensuring safe exploration is a critical area of research.
- Interpretability: Like many deep learning systems, the decision-making process of a complex DRL agent can be a “black box,” making it difficult to trust and debug.
TThe Future of Reinforcement Learning: Navigating the Next Frontier of AI
The field of Reinforcement Learning is undergoing a remarkable transformation, pushing beyond game-playing achievements toward solving real-world problems. While current Reinforcement Learning systems have demonstrated impressive capabilities, several key frontiers are emerging that will define the next generation of intelligent systems. Understanding these directions is crucial for grasping where AI is headed next.
1. Improving Sample Efficiency: Learning More from Less
One of the most significant bottlenecks in practical Reinforcement Learning is sample inefficiency. Current state-of-the-art algorithms often require millions of interactions to learn simple tasks, making real-world deployment prohibitively expensive and time-consuming. The future lies in developing approaches that can learn effectively from limited experience.
- Meta-Learning (“Learning to Learn”): This revolutionary approach involves training agents that can quickly adapt to new tasks with minimal additional data. Imagine an agent that has learned to play multiple video games; through meta-learning, it could develop a general understanding of game mechanics that allows it to master a completely new game in just a few attempts. This is achieved by exposing the agent to a distribution of tasks during training, forcing it to internalize broader patterns and strategies rather than just memorizing solutions to specific problems.
- Advanced Exploration Strategies: Traditional exploration methods like ε-greedy are often inefficient. Newer approaches include:
- Intrinsic Motivation: Agents generate their own internal rewards for discovering novel states or learning new skills, much like human curiosity drives learning.
- Bayesian Optimization: Using probabilistic models to guide exploration toward areas with the highest potential information gain.
- State-Counting Methods: Encouraging agents to visit states they haven’t experienced frequently, ensuring comprehensive environment coverage.
- Model-Based Methods: Instead of learning purely through trial-and-error, model-based Reinforcement Learning involves learning the environment’s dynamics—essentially creating an internal simulation. Once the agent understands how the world works, it can plan ahead by mentally simulating different action sequences, dramatically reducing the need for physical interactions. Recent advances in uncertainty-aware models have made this approach more practical by helping agents recognize when their predictions are unreliable.
2. Multi-Agent Reinforcement Learning (MARL): The Social Dimension of AI
Real-world environments rarely involve isolated agents. MARL addresses the complex dynamics that emerge when multiple learning agents interact, creating systems that are more reflective of actual social and economic environments.
")
- Emergent Behaviors: In MARL systems, complex group behaviors can emerge from simple individual learning rules. This has fascinating implications for:
- Autonomous Traffic Flow: Where self-driving cars learn to coordinate for optimal traffic patterns
- Economic Market Simulation: Creating realistic models of market dynamics with adaptive traders
- Collaborative Robotics: Multiple robots learning to work together on complex manufacturing tasks
- Key Challenges in MARL:
- Non-Stationarity: From any single agent’s perspective, the environment appears to keep changing because other agents are simultaneously learning and adapting.
- Credit Assignment: Determining which agent’s actions contributed to a shared outcome becomes increasingly difficult as the number of agents grows.
- Communication Protocols: Developing effective ways for agents to share information and coordinate their strategies.
Recent breakthroughs in MARL have shown promising results in complex multi-player games like Dota 2 and StarCraft II, demonstrating the potential for sophisticated multi-agent coordination.
3. Hierarchical Reinforcement Learning: Thinking in Terms of Subgoals
Human intelligence naturally breaks down complex tasks into manageable subcomponents. Hierarchical Reinforcement Learning aims to replicate this capability by enabling agents to operate at multiple levels of temporal abstraction.
- The Subgoal Paradigm: Instead of learning a single monolithic policy, hierarchical agents learn to set and achieve subgoals. For example, a robot tasked with “making coffee” might break this down into subgoals like “find the kitchen,” “locate coffee maker,” “add water,” etc., with each subgoal having its own learning process.
- Benefits of Hierarchy:
- Transfer Learning: Skills learned at lower levels can be reused across different high-level tasks
- Improved Exploration: Agents can explore more strategically by changing subgoals rather than primitive actions
- Scalability: Makes extremely long-horizon tasks feasible by dividing them into manageable chunks
- Implementation Approaches:
- Options Framework: Formalizing the concept of temporally extended actions
- Feudal Networks: Inspired by hierarchical management structures, with managers setting goals for workers
- Skill Discovery: Algorithms that automatically identify useful subbehaviors from experience
4. Integration with Large Language Models (LLMs): Combining Reasoning with Action
The fusion of Reinforcement Learning with large language models represents one of the most exciting frontiers in AI, creating systems that combine the reasoning capabilities of LLMs with the decision-making power of Reinforcement Learning.
- Natural Language Guidance: LLMs can provide high-level strategic guidance to Reinforcement Learning agents, interpreting complex instructions and breaking them down into actionable steps. For instance, an agent could receive natural language commands like “be more cautious near cliffs” and incorporate this guidance into its learning process.
- World Knowledge Integration: LLMs contain vast amounts of commonsense knowledge about the world. By integrating this knowledge, Reinforcement Learning agents can start with better priors about how the world works, dramatically accelerating learning. An agent tasked with kitchen chores would benefit from the LLM’s understanding that dishes are typically found in cabinets and that water comes from taps.
- Explainable Policies: LLMs can help translate the often-opaque decision-making processes of Reinforcement Learning agents into human-understandable explanations, addressing the “black box” problem that has long plagued deep reinforcement learning.
- Procedural Knowledge: While LLMs excel at declarative knowledge, Reinforcement Learning provides the mechanism for learning procedural knowledge—the “how” rather than just the “what.” Together, they create more complete intelligent systems.
5. Offline Reinforcement Learning: Learning from Historical Data
Perhaps the most practical advancement for real-world applications, offline Reinforcement Learning (also known as batch reinforcement learning) enables learning from pre-collected datasets without any active environment interaction.
")
- The Paradigm Shift: Traditional Reinforcement Learning requires active exploration, which is dangerous or impossible in domains like healthcare, autonomous driving, or industrial control. Offline Reinforcement Learning learns from historical data, much like supervised learning, but with the goal of optimizing sequential decisions rather than making single predictions.
- Key Applications:
- Healthcare: Learning optimal treatment policies from electronic health records
- Autonomous Systems: Improving driving policies from historical driving data
- Robotics: Learning manipulation skills from previously collected demonstrations
- Recommendation Systems: Optimizing long-term user engagement from historical interaction logs
- Technical Challenges:
- Distributional Shift: The fundamental problem that the agent must learn a policy that might choose actions different from those in the dataset, potentially leading to unpredictable performance when deployed.
- Uncertainty Quantification: Developing methods that can accurately estimate the uncertainty of value predictions for state-action pairs not well-covered by the dataset.
- Conservative Learning: Algorithms that avoid the extrapolation errors that occur when asked to evaluate actions significantly different from those in the training data.
Recent algorithms like Conservative Q-Learning (CQL) and Behavior Regularized Actor-Critic (BRAC) have made significant progress in addressing these challenges, making offline Reinforcement Learning increasingly practical for real-world deployment.
The Converging Future
These frontiers are not developing in isolation—the most powerful future systems will likely integrate multiple approaches. We can envision agents that use hierarchical structures to break down complex tasks, leverage LLMs for reasoning and knowledge, learn efficiently through model-based planning, and safely transfer policies from offline pre-training to online fine-tuning. As these technologies mature.
Reinforcement Learning will transition from primarily solving simulated environments to becoming a core technology powering adaptive, intelligent systems in the real world, from personalized education and healthcare to autonomous transportation and beyond. The future of Reinforcement Learning is not just about creating better algorithms, but about developing complete learning systems that can operate safely, efficiently, and intelligently in the complex, messy reality of human environments.
Conclusion
Reinforcement Learning represents one of the most general and powerful paradigms in artificial intelligence, offering a framework for learning optimal behavior through interaction and feedback. From mastering the abstract strategy of Go to controlling complex physical systems, its successes have demonstrated a path toward creating truly autonomous agents.
While significant challenges in efficiency, safety, and reliability remain, the relentless pace of innovation continues to push the boundaries of what is possible. As algorithms become more sample-efficient, safe, and capable of handling multi-agent and hierarchical tasks, the applications of Reinforcement Learning will only broaden, solidifying its role as a cornerstone technology in the quest for general artificial intelligence. Understanding the principles and potential of Reinforcement Learning is, therefore, essential for anyone looking to be at the forefront of AI research and development.