Master data lakes: Learn how to store, manage, and analyze massive datasets. Our 2025 guide shows you how to build scalable data solutions for business intelligence and AI.
Have you ever tried to organize a massive, messy garage? You’ve got boxes of old photos, tools you might need someday, sports equipment, and holiday decorations. It’s all valuable, but it’s a jumble. You can’t find anything when you need it, and you have no idea what treasures are hidden in those boxes.
For decades, companies have treated their data a lot like that messy garage. They had separate, neatly organized shelves for specific things—a customer database here, a sales spreadsheet there. This is the traditional data warehouse. It’s great for data lakes the stuff you know you need, like your everyday tools.
But what about everything else? The thousands of hours of customer support calls? The raw clickstreams from your website? The social media feeds and sensor data from factory machines? This information is massive, unstructured, and potentially incredibly valuable. It doesn’t fit on the neat shelves.
This is where data lakes come in.
Imagine instead of a garage with shelves, you had a giant, secure, and perfectly indexed data lakes. You could just pour all your data into it—every spreadsheet, every image, every log file, every sound recording. You wouldn’t need to sort it first. You could figure out what to do with it later.
In this guide, we’re going to wade into the world of data lakes. We’ll break down what they are, why they’re a game-changer, and how you can build and use one to unlock insights you never knew you had. Let’s dive in.
What is a Data Lake? (The Giant Reservoir Analogy)
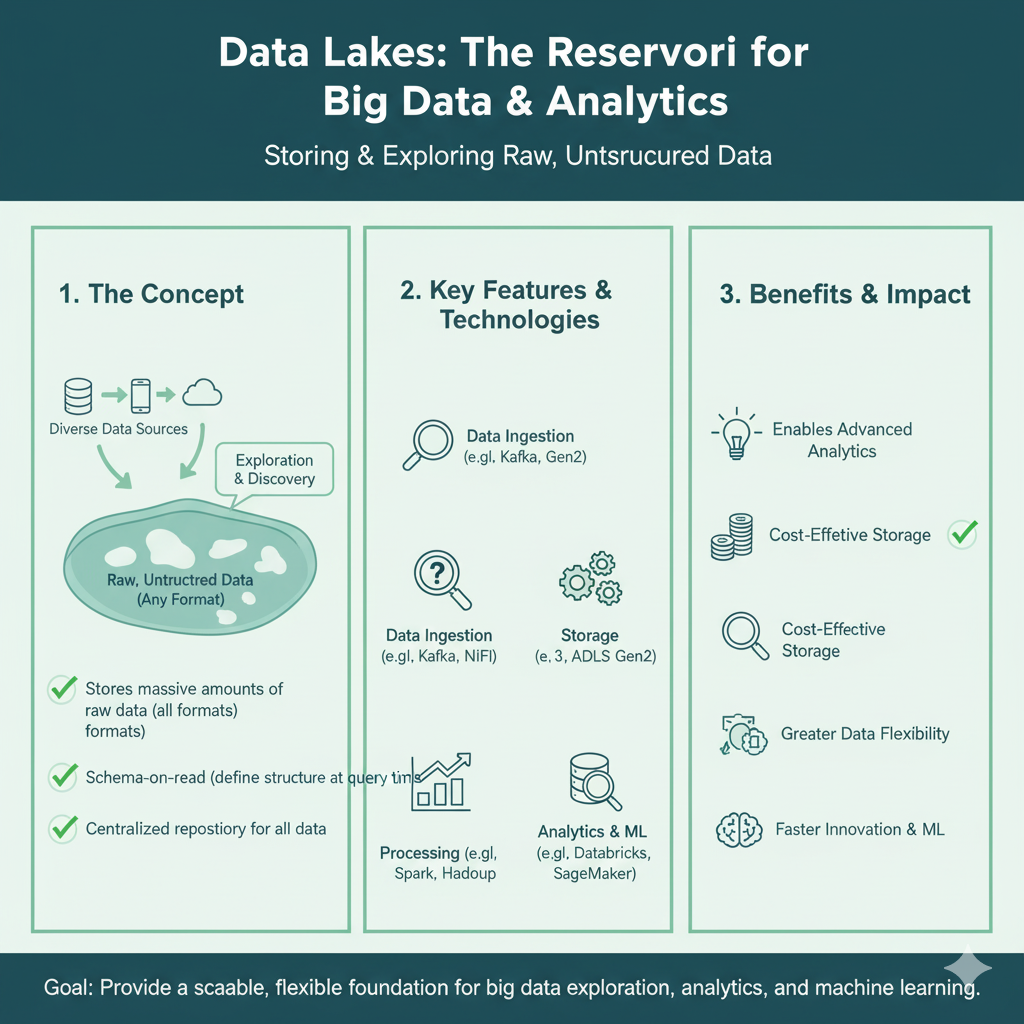
Let’s make this concept crystal clear. A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale.
Think of it like a real data lakes being fed by multiple rivers.
- The Lake: This is the data lake itself, typically built on cheap, scalable cloud storage like Amazon S3, Azure Data Lakes Storage, or Google Cloud Storage.
- The Rivers (Data Sources): These are all the places your data comes from. Each river is a different source.
- River 1: Customer data from your CRM (like Salesforce).
- River 2: Website clickstream data.
- River 3: Social media feeds.
- River 4: IoT sensor data from equipment.
- River 5: Excel files from your marketing team.
- The Water (The Data): This is the actual data itself, in all its forms.
- Structured Data: Clear, organized water. data lakes This is data that fits neatly into tables with rows and columns, like your customer database.
- Semi-structured Data: Water with some sediment. This is data like JSON, XML, or CSV files—it has some organization but isn’t rigid.
- Unstructured Data: Murky water with algae, fish, and rocks. This is the bulk of modern data: emails, PDFs, videos, audio recordings, and images.
In a data lake, you store it all. You don’t throw anything away. You just pour it in.
Data Lake vs. Data Warehouse: What’s the Difference?
This is the most common question, and it’s crucial. They are both storage solutions, but they serve very different purposes.
| Data Lake | Data Warehouse | |
|---|---|---|
| Data Type | All data: structured, semi-structured, unstructured. | Primarily structured, cleaned data. |
| Schema | Schema-on-Read: You define the structure when you read the data for analysis. | Schema-on-Write: You must define the structure before you write the data. |
| Cost | Relatively cheap (object storage). | More expensive (proprietary databases). |
| Users | Data scientists, data engineers, analysts. | Business analysts, executives. |
| Analytics | Advanced analytics, machine learning, real-time analytics. | Batch reporting, Business Intelligence (BI), dashboards. |
| Flexibility | Highly agile and adaptable to change. | Rigid; changes are difficult and costly. |
The Simple Analogy:
- A Data Warehouse is like a bottled water factory. Water is purified, structured, and packaged into specific bottles (reports) for easy consumption. You know exactly what you’re getting.
- A Data Lake is the natural spring itself. It contains all the water in its raw form. You can bottle it, use it for power, swim in it, or analyze its minerals. The possibilities are endless, but it requires work to use.
Why Your Business Needs a Data Lake in 2025
You might be thinking, “My databases are working just fine.” And for many routine reports, they are. But data lakes unlock new capabilities that are becomingdata lakes essential.
1. They Break Down Data Silos
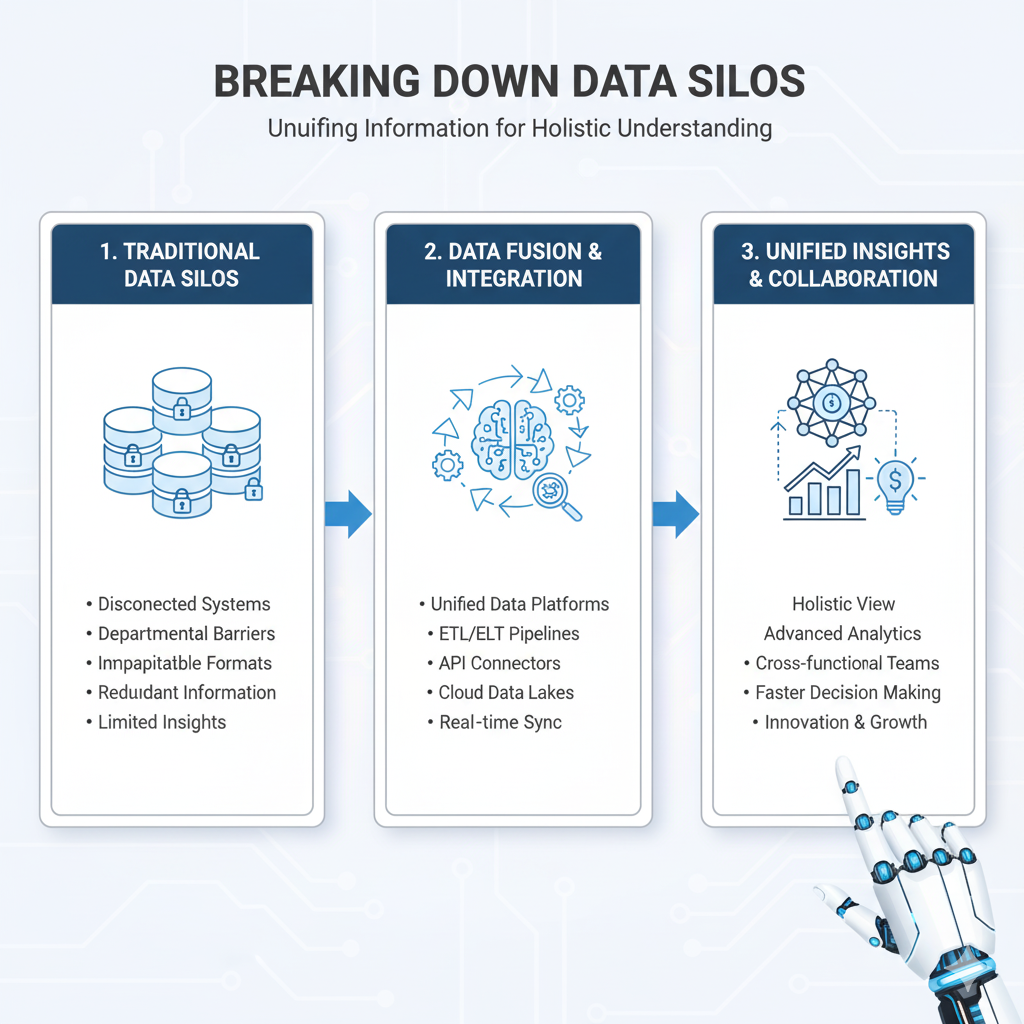
In most companies, data is trapped. The marketing team has its data, the sales team has theirs, and the engineering team has another set. These are data silos. A data lake acts as a single source of truth for the entire organization. By pouring all these separate streams into one lake, you can finally see the whole picture. You can answer questions like, “How does our social media sentiment (marketing data) correlate with our sales figures (sales data) and product usage (engineering data)?”
2. They Enable Advanced Analytics and Machine Learning
This is the killer app for data lakes. Machine learning models thrive on massive, diverse datasets. You can’t train a model to predict machine failure with just a simple table. You need the raw sensor data, the maintenance logs (often PDFs), and the technician notes. A data lake is the only place where all this diverse data can co-exist and be used to train powerful AI models.
3. They are Cost-Effective for Storing Everything
Storage on cloud platforms like S3 is incredibly cheap. This “store now, analyze later” philosophy means you never have to make the painful decision to delete potentially valuable data because it’s too expensive to keep. You can keep all your raw data forever, which is perfect for historical analysis and auditing.
4. They Offer Unmatched Flexibility
With a traditional warehouse, if your business question changes, you often have to redesign the entire database—a costly and slow process. With a data lake, the data is just there. A data scientist can ask a new question tomorrow and immediately start analyzing the raw data that’s been sitting in the lake for years, without data lakesneeding to ask an engineer to restructure anything.
The Architecture of a Data Lake: How It’s Built
Building a useful data lake is more than just creating a cloud storage bucket and dumping files in it. A well-architected lake has distinct zones, like a water treatment plant.
The Four Essential Zones of a Data Lake
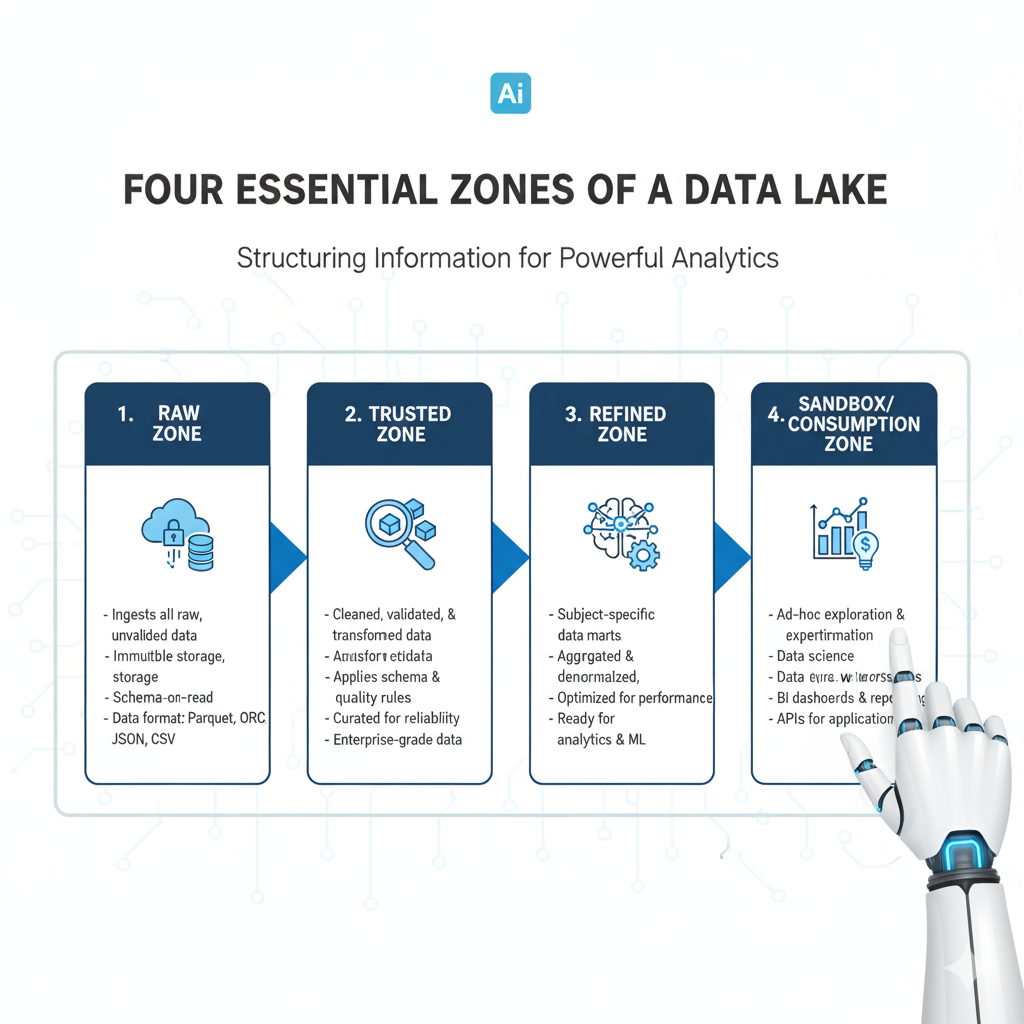
- The Landing Zone (or Transient Zone): This is the “docking area” for new data. Data arrives here in its original, raw format. No changes are made. This is your backup; if anything goes wrong in processing, you can always come back to the original file.
- Example: A raw CSV dump from the database lands here.
- The Raw Zone (or Bronze Layer): Data is moved here from the landing zone. It’s still in its original format, but it’s now stored for the long term. This zone is immutable, meaning it can’t be changed. This is the single source of truth.
- Example: The same CSV file now sits in the Raw Zone, renamed with a timestamp.
- The Curated Zone (or Silver/Gold Layer): This is where the magic happens. Data is cleaned, transformed, and enriched.
- Silver Layer: Data from the Raw Zone is cleaned. Duplicates are removed, bad records are filtered out, and data is standardized (e.g., “USA” and “U.S.A.” become “United States”).
- Gold Layer: Data is aggregated and shaped for business consumption. This is where you create tables that look familiar to business users, like a clean “Customer 360” table that combines data from a dozen different sources.
- The Sandbox Zone: This is a playground for data lakes scientists. They can take data from any zone and experiment with it, build models, and test hypotheses without affecting the other, more structured zones.
A Step-by-Step Guide to Building Your First Data Lake
Let’s make this practical. How would you start building a data lake for a medium-sized business?
Step 1: Define Your Business Goals
Never start with the technology. Start with the question: “What problem are we trying to solve?”
- Do we want to predict which customers will churn?
- Do we want to understand the customer journey across our website and app?
- Do we want to analyze sensor data to do data lakes predictive maintenance on our equipment?
Your goals will determine what data you need to collect.
Step 2: Choose Your Cloud Platform
For 99% of companies, building a data lake in the cloud is the right choice. The big three are:
- Amazon Web Services (AWS): S3 for storage, Glue for data cataloging, Athena for querying.
- Microsoft Azure: Azure Data Lake Storage (Gen2), Azure Data Factory, Synapse Analytics.
- Google Cloud Platform (GCP): Google Cloud Storage, Dataflow, BigQuery.
For this example, let’s use AWS as it’s the most common.
Step 3: Ingest Your Data (The Rivers)
You need to get data flowing into your data lakes. You can use:
- AWS Database Migration Service (DMS): To continuously replicate data from your operational databases (like PostgreSQL or MySQL) into S3.
- AWS Glue: To schedule jobs that pull data from other sources, like SaaS applications.
- Apache Kafka: For real-time streaming data from websites or apps.
Step 4: Catalog and Secure the Data
A data lake without a catalog is a “data swamp”—a messy, unusable pond. You must know what data you have, where it is, and what it contains.
- Use a Data Catalog: AWS Glue Data Catalog automatically crawls your S3 buckets, discovers data, and records its schema and location.
- Implement Security: Use AWS IAM roles and policies data lakes to control who can see what data. This is non-negotiable.
Step 5: Process and Analyze
Now, make the data useful.
- Process with AWS Glue ETL: Write scripts to clean and transform data from the Raw Zone to the Curated Zone.
- Analyze with Amazon Athena: Use standard SQL to query data directly in S3. It’s perfect for ad-hoc analysis.
- Build ML Models with Amazon SageMaker: Use the data in your data lakes to train and deploy machine learning models.
Real-World Use Cases: Data Lakes in Action
Use Case 1: The E-commerce Company
- Goal: Personalize the shopping experience to increase sales.
- Data Ingested:
- Structured: Customer profiles, past purchase history, product catalog.
- Semi-structured: Website clickstream data (every click, hover, and scroll).
- Unstructured: Customer product reviews and images.
- The Analysis: By analyzing the clickstream data in the data lake, they can see that customers who look at hiking boots often later look at rain jackets. They use this to create a real-time recommendation engine: “Customers who viewed this item also viewed…”
Use Case 2: The Manufacturing Company
- Goal: Predict equipment failure to avoid costly downtime.
- Data Ingested:
- Structured: Maintenance logs, parts inventory.
- Semi-structured: Real-time sensor data from machines (temperature, vibration, pressure).
- Unstructured: Technician notes (from voice-to-text), repair manual PDFs.
- The Analysis: Data scientists build a machine learning model in the data lake that correlates specific vibration patterns (from sensor data) with future breakdowns (from maintenance logs). The system can now alert the maintenance team days before a failure is likely to happen.
Use Case 3: The Healthcare Provider
- Goal: Improve patient outcomes through better research.
- Data Ingested:
- Structured: Patient lab results, medication records.
- Unstructured: Doctor’s notes, MRI and X-ray images, genomic sequencing data.
- The Analysis: Researchers can query the data lake to find patients with similar symptoms and genomic markers. They can analyze which treatments were most effective, leading to more personalized and successful care plans.
Common Pitfalls and How to Avoid Them (The “Data Swamp”)
The biggest risk with a data lake is that it turns into a data swamp—a costly, disorganized dump where no one can find anything useful. Here’s how to avoid it.
Pitfall 1: Dumping Data Without Governance
- The Mistake: Just pouring data in with no plan, no catalog, and no ownership.
- The Solution: Implement a data governance framework from day one. Assign data owners. Use a data catalog to keep track of everything.
Pitfall 2: Ignoring Data Quality
- The Mistake: Assuming that all data in the data lakes is ready for analysis.
- The Solution: Be transparent about data quality. Use your zones effectively. Clearly label datasets in the Curated Zone as “trusted” and datasets in the Raw Zone as “use with caution.”
Pitfall 3: Poor Security
- The Mistake: Giving everyone access to everything.
- The Solution: Apply the principle of least privilege. Use role-based access control (RBAC) to ensure people only see the data they are authorized to see.
Pitfall 4: Lack of a Clear Strategy
- The Mistake: Building a data lakes because it’s trendy, with no business goals.
- The Solution: Go back to Step 1. Tie every piece of data you ingest to a specific business outcome.
Frequently Asked Questions (FAQs)
Q1: Is a data lake only for huge companies with “Big Data”?
Not at all! While data lakes are designed to handle massive scale, even mid-sized companies can benefit. The low cost of cloud storage means you can start small with a few key data sources and grow your data lakes as your needs evolve. The flexibility is valuable for businesses of any size.
Q2: How much does it cost to build and maintain a data lake?
The cost is primarily the cloud storage (e.g., S3), which is very cheap, and the computing power for processing and querying. You only pay for what you use. The initial setup can be done with a few hundred dollars a month, and costs scale linearly with your data and usage.
Q3: What skills does my team need to manage a data lake?
You’ll need a mix of skills:
- Data Engineers: To build the pipelines that move and transform data.
- Data Scientists/Analysts: To analyze the data and build models.
- Cloud Architects: To manage the underlying infrastructure and security.
Many of these skills can be learned, and cloud providers offer managed services that reduce the operational burden.
Q4: Can a data lake replace my data warehouse?
In some modern architectures, yes (this is called the “data lakes house”). But for most companies, they are complementary. The data lake stores all the raw data and is used for exploration and advanced analytics. The data warehouse takes cleaned data from the data lakes and serves it to business users for fast, reliable reporting and dashboards. They work together.
Conclusion: Dive In, the Water’s Fine
We started with the image of a messy garage, overwhelmed by the chaos of valuable stuff. A data lake offers a better way—a vast, organized reservoir where every piece of data has a place and a purpose.
Mastering data lakes isn’t just about learning a new technology; it’s about adopting a new mindset. It’s about being curious, about believing that the answers to your next big business breakthrough are already hidden in the data you’re already collecting. It’s about being prepared for questions you haven’t even thought to ask yet.
The journey begins with a single step. Start by identifying one valuable but underused data source in your company. It could be your website logs, your customer support tickets, or your marketing campaign data. Pour it into a cloud storage bucket. Catalog it. See what you can learn from it.
You don’t have to build the perfect data lakes on day one. Start small, learn, and expand. The ability to store, manage, and analyze all your data is no longer a luxury for tech giants; it’s a fundamental capability for any organization that wants to thrive in the digital age. Your data has stories to tell. It’s time to give it a place to speak.