Master data lifecycle optimization with our comprehensive guide. Learn 8-stage framework to improve data quality, enhance security, ensure compliance, and maximize business value across entire data journey
Introduction: The Strategic Imperative of Data Lifecycle Management
In today’s data-driven economy, organizations that master the Data lifecycle gain significant competitive advantages through improved decision-making, operational efficiency, and innovation capabilities. The Data lifecycle encompasses the complete journey of data from its initial creation and acquisition through processing, storage, utilization, and eventual archival or destruction. Understanding and optimizing this Data lifecycle is no longer a technical concern confined to IT departments—it has become a strategic business imperative that directly impacts organizational performance, compliance posture, and market positioning.
The complexity of modern Data lifecycle management has increased exponentially as organizations grapple with unprecedented data volumes, diverse data types, stringent regulatory requirements, and escalating security threats. According to recent industry surveys, enterprises now manage data across an average of 900 different applications and systems, creating significant challenges for maintaining Data lifecycle consistency, quality, and governance. Furthermore, the global data sphere is projected to grow from 64 zettabytes in 2020 to over 180 zettabytes by 2025, making effective Data lifecycle management not just advantageous but essential for organizational survival.
This comprehensive guide explores the framework for optimizing the entire Data lifecycle to enhance data quality, strengthen security protocols, and maximize business value. We’ll examine each phase of the Data lifecycle in detail, providing practical strategies, best practices, and real-world examples that organizations can implement to transform their data from a passive asset into an active strategic resource. By taking a holistic approach to Data lifecycle management, organizations can ensure their data remains accurate, accessible, secure, and valuable throughout its entire existence.
Understanding the Data Lifecycle Framework
The Eight-Stage Data Lifecycle Model
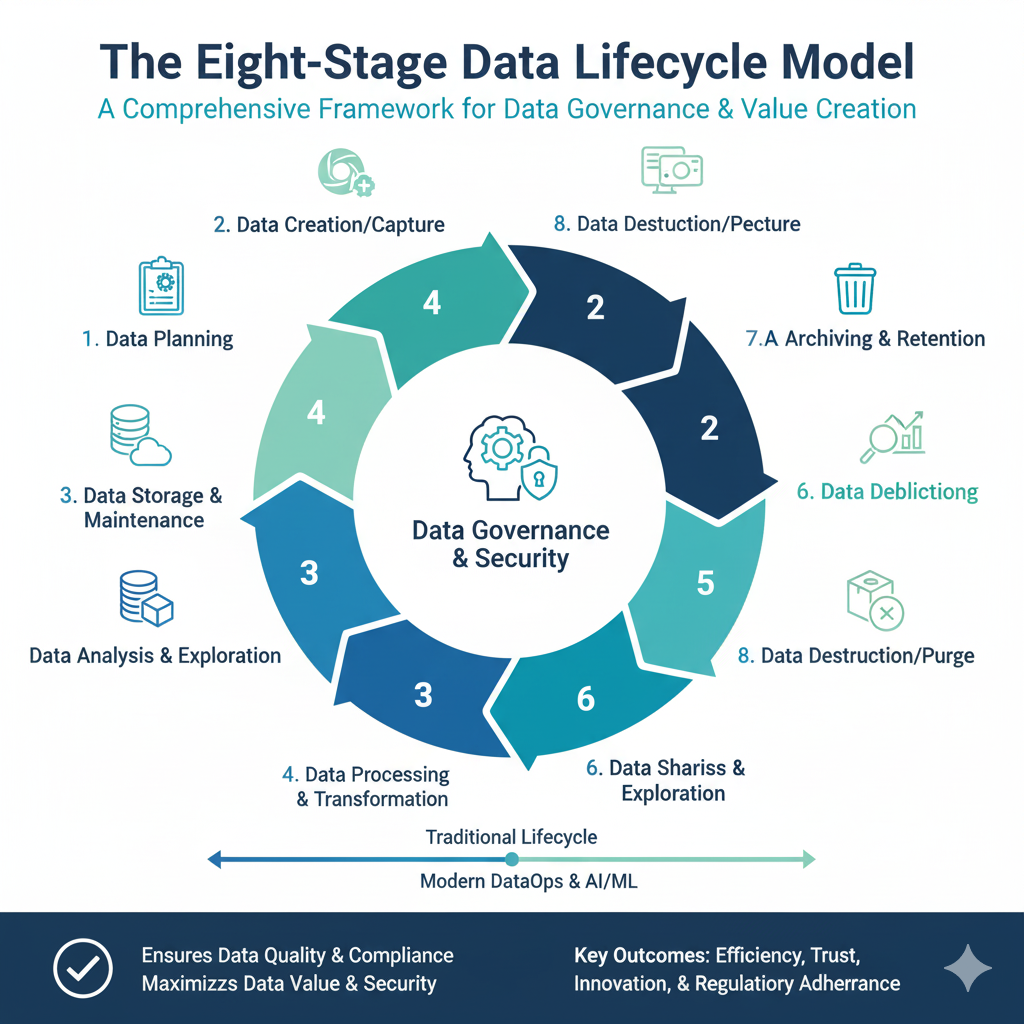
The modern Data lifecycle consists of eight interconnected stages that collectively ensure data remains a valuable organizational asset:
- Data Creation and Acquisition
- Data Storage and Organization
- Data Processing and Transformation
- Data Analysis and Utilization
- Data Sharing and Distribution
- Data Archival and Retention
- Data Destruction and Disposal
- Data Governance and Quality Management
Each stage of the Data lifecycle presents unique challenges and opportunities for optimization. Organizations that successfully manage the entire Data lifecycle can achieve up to 40% reduction in data management costs while improving data quality by 60% and accelerating time-to-insight by 50%.
The Evolution of Data Lifecycle Management
Traditional Data lifecycle management focused primarily on storage optimization and basic data governance. However, the modern approach recognizes that effective Data lifecycle management must balance multiple competing priorities:
- Quality vs. Speed: Ensuring data accuracy while maintaining accessibility
- Security vs. Accessibility: Protecting sensitive data while enabling legitimate use
- Retention vs. Cost: Maintaining historical data while controlling storage expenses
- Compliance vs. Innovation: Meeting regulatory requirements while enabling data exploration
Stage 1: Data Creation and Acquisition Optimization
Strategic Data Sourcing and Collection
The foundation of an effective Data lifecycle begins with how data enters the organization. Optimizing this initial stage sets the trajectory for data quality and usability throughout the entire Data lifecycle.
Best Practices for Data Creation:
python
class DataAcquisitionFramework:
"""
Framework for optimizing data creation and acquisition
"""
def __init__(self):
self.data_sources = {}
self.quality_metrics = {}
def implement_data_quality_gates(self, data_stream):
"""
Implement quality checks at point of entry
"""
quality_gates = {
'completeness_threshold': 0.95,
'accuracy_threshold': 0.98,
'timeliness_threshold': '5 minutes',
'validity_rules': self._load_validity_rules()
}
validation_results = self._validate_data_quality(data_stream, quality_gates)
if validation_results['pass']:
return self._process_valid_data(data_stream)
else:
return self._handle_quality_issues(data_stream, validation_results)
def establish_data_provenance(self, metadata):
"""
Track data lineage and provenance from creation
"""
provenance_record = {
'source_system': metadata['source'],
'creation_timestamp': datetime.utcnow(),
'data_owner': metadata['owner'],
'collection_method': metadata['method'],
'quality_scores': self._calculate_initial_quality(metadata),
'processing_history': []
}
return self._store_provenance(provenance_record)
def optimize_data_collection_strategy(self, data_requirements):
"""
Design efficient data collection based on business needs
"""
collection_framework = {
'real_time_sources': self._identify_real_time_needs(data_requirements),
'batch_sources': self._optimize_batch_collection(data_requirements),
'external_data_acquisition': self._manage_external_sources(data_requirements),
'data_minimization': self._implement_data_minimization(data_requirements)
}
return collection_framework
Key Optimization Strategies:
- Implement Data Quality Gates: Establish validation rules that data must pass before entering organizational systems
- Standardize Data Formats: Create consistent data structures and formats across all acquisition channels
- Automate Data Collection: Reduce manual intervention through automated data pipelines and APIs
- Document Data Provenance: Capture metadata about data origin, collection methods, and initial quality metrics
Data Source Evaluation and Selection

Organizations must critically evaluate data sources throughout the Data lifecycle to ensure reliability and relevance:
python
def evaluate_data_sources(source_candidates, business_requirements):
"""
Evaluate and score potential data sources
"""
evaluation_framework = {
'reliability_metrics': {
'uptime_percentage': 0.99,
'error_rate': 0.01,
'historical_performance': 'excellent'
},
'quality_metrics': {
'completeness_score': 0.95,
'accuracy_rating': 'high',
'timeliness_index': 'real_time'
},
'cost_considerations': {
'acquisition_cost': 'calculate_roi',
'maintenance_cost': 'include_total_cost',
'processing_cost': 'estimate_complexity'
},
'compliance_factors': {
'gdpr_compliance': True,
'data_sovereignty': 'evaluate_restrictions',
'license_restrictions': 'review_terms'
}
}
scored_sources = []
for source in source_candidates:
score = calculate_source_score(source, evaluation_framework)
if score >= business_requirements['minimum_score']:
scored_sources.append({
'source': source,
'score': score,
'recommendation': 'approve' if score > 0.8 else 'review'
})
return sorted(scored_sources, key=lambda x: x['score'], reverse=True)
Stage 2: Data Storage and Organization Excellence
Modern Data Architecture for Lifecycle Management
Effective data storage organization is crucial throughout the Data lifecycle for ensuring accessibility, performance, and cost-efficiency.
Multi-Tier Storage Strategy:
python
class DataStorageOptimizer:
"""
Optimize data storage across the lifecycle
"""
def __init__(self):
self.storage_tiers = {
'hot_storage': {
'purpose': 'frequent_access',
'performance': 'high',
'cost': 'premium',
'retention': '30_days'
},
'warm_storage': {
'purpose': 'regular_access',
'performance': 'medium',
'cost': 'balanced',
'retention': '1_year'
},
'cold_storage': {
'purpose': 'infrequent_access',
'performance': 'low',
'cost': 'economy',
'retention': '7_years'
},
'archive_storage': {
'purpose': 'compliance_retention',
'performance': 'very_low',
'cost': 'minimal',
'retention': 'indefinite'
}
}
def implement_data_classification(self, data_assets):
"""
Classify data for appropriate storage tiering
"""
classification_framework = {
'access_frequency': self._analyze_access_patterns(data_assets),
'business_criticality': self._assess_business_impact(data_assets),
'security_requirements': self._evaluate_security_needs(data_assets),
'compliance_obligations': self._identify_retention_requirements(data_assets)
}
storage_assignments = {}
for asset in data_assets:
classification_score = self._calculate_classification_score(
asset, classification_framework)
storage_tier = self._assign_storage_tier(classification_score)
storage_assignments[asset['id']] = storage_tier
return storage_assignments
def optimize_storage_costs(self, usage_patterns):
"""
Implement cost optimization strategies
"""
optimization_strategies = {
'data_compression': self._apply_compression_algorithms(),
'deduplication': self._implement_deduplication(),
'tiered_storage': self._automate_tier_migration(),
'lifecycle_policies': self._enforce_retention_policies()
}
return self._calculate_cost_savings(optimization_strategies)
Data Organization and Cataloging
A well-organized data catalog is essential for effective Data lifecycle management:
python
def implement_data_catalog(data_assets):
"""
Create comprehensive data catalog for lifecycle management
"""
catalog_structure = {
'business_glossary': {
'data_domains': define_data_domains(),
'business_terms': establish_business_vocabulary(),
'data_owners': assign_data_stewardship()
},
'technical_metadata': {
'data_schemas': document_data_structures(),
'data_lineage': map_data_flows(),
'quality_metrics': track_data_quality()
},
'operational_metadata': {
'access_patterns': monitor_usage_trends(),
'performance_metrics': track_system_performance(),
'cost_analytics': analyze_storage_costs()
}
}
return build_data_catalog(data_assets, catalog_structure)
Stage 3: Data Processing and Transformation Optimization
Streamlining Data Preparation
Efficient data processing is critical for maintaining data quality and usability throughout the Data lifecycle.
Data Processing Framework:
python
class DataProcessingOptimizer:
"""
Optimize data processing across the lifecycle
"""
def implement_etl_optimization(self, data_pipelines):
"""
Optimize Extract, Transform, Load processes
"""
optimization_techniques = {
'incremental_processing': self._design_incremental_loads(),
'parallel_processing': self._implement_parallel_execution(),
'data_validation': self._integrate_quality_checks(),
'error_handling': self._create_resilient_pipelines()
}
optimized_pipelines = []
for pipeline in data_pipelines:
optimized_pipeline = self._apply_optimizations(pipeline, optimization_techniques)
optimized_pipelines.append(optimized_pipeline)
return optimized_pipelines
def automate_data_quality_monitoring(self, data_assets):
"""
Implement continuous data quality assessment
"""
quality_framework = {
'completeness_checks': self._monitor_missing_values(),
'accuracy_validation': self._verify_data_accuracy(),
'consistency_monitoring': self._ensure_data_consistency(),
'timeliness_tracking': self._measure_data_freshness()
}
quality_metrics = {}
for asset in data_assets:
asset_quality = self._calculate_quality_scores(asset, quality_framework)
quality_metrics[asset['id']] = asset_quality
# Trigger alerts for quality issues
if asset_quality['overall_score'] < 0.9:
self._trigger_quality_alert(asset, asset_quality)
return quality_metrics
Transformation and Enrichment Strategies
Data transformation plays a vital role in enhancing data value throughout the Data lifecycle:
python
def implement_data_enrichment(raw_data, enrichment_strategies):
"""
Enhance data value through strategic enrichment
"""
enrichment_framework = {
'geographic_enrichment': add_geographic_context(raw_data),
'temporal_enrichment': add_time-based_features(raw_data),
'demographic_enrichment': append_demographic_attributes(raw_data),
'behavioral_enrichment': incorporate_behavioral_insights(raw_data),
'external_data_integration': merge_external_datasets(raw_data)
}
enriched_data = apply_enrichment_strategies(raw_data, enrichment_strategies)
# Track enrichment impact on data quality
quality_improvement = measure_quality_impact(raw_data, enriched_data)
return {
'enriched_data': enriched_data,
'quality_impact': quality_improvement,
'enrichment_metadata': document_enrichment_process()
}
Stage 4: Data Analysis and Utilization Enhancement
Maximizing Data Value Through Advanced Analytics
The analysis phase represents where data generates tangible business value in the Data lifecycle.
Analytical Framework Optimization:
python
class DataAnalysisOptimizer:
"""
Optimize data analysis and utilization
"""
def implement_analytical_governance(self, analytical_processes):
"""
Govern analytical processes for quality and compliance
"""
governance_framework = {
'model_management': self._govern_analytical_models(),
'result_validation': self._validate_analytical_outputs(),
'bias_detection': self._monitor_algorithmic_bias(),
'interpretability_standards': self._ensure_result_interpretability()
}
governed_processes = []
for process in analytical_processes:
governed_process = self._apply_governance_framework(process, governance_framework)
governed_processes.append(governed_process)
return governed_processes
def optimize_analytical_performance(self, analytical_workloads):
"""
Enhance performance of analytical processes
"""
performance_optimizations = {
'query_optimization': self._optimize_data_queries(),
'caching_strategies': self._implement_intelligent_caching(),
'resource_management': self._optimize_compute_resources(),
'data_partitioning': self._design_efficient_data_structures()
}
performance_metrics = {}
for workload in analytical_workloads:
optimized_workload = self._apply_performance_optimizations(
workload, performance_optimizations)
performance_metrics[workload['id']] = self._measure_performance_improvement(
workload, optimized_workload)
return performance_metrics
Business Intelligence and Reporting Optimization
Effective reporting ensures data insights drive business decisions throughout the Data lifecycle:
python
def optimize_business_intelligence(data_assets, user_requirements):
"""
Enhance BI capabilities for maximum impact
"""
bi_optimization_framework = {
'dashboard_design': create_intuitive_interfaces(),
'report_automation': implement_scheduled_reporting(),
'self_service_analytics': enable_user_empowerment(),
'mobile_optimization': ensure_cross_device_accessibility(),
'performance_monitoring': track_usage_and_engagement()
}
optimized_bi_environment = build_bi_platform(
data_assets, user_requirements, bi_optimization_framework)
# Measure BI effectiveness
effectiveness_metrics = {
'user_adoption_rate': calculate_adoption_metrics(),
'decision_impact': measure_business_impact(),
'time_to_insight': analyze_insight_velocity(),
'user_satisfaction': collect_feedback_scores()
}
return {
'optimized_platform': optimized_bi_environment,
'effectiveness_metrics': effectiveness_metrics
}
Stage 5: Data Security and Protection Framework
Comprehensive Data Security Throughout the Lifecycle
Security must be integrated into every phase of the Data lifecycle to protect against evolving threats.
Security Implementation Framework:
python
class DataSecurityManager:
"""
Manage data security across the entire lifecycle
"""
def __init__(self):
self.security_controls = {}
self.threat_monitoring = {}
def implement_layered_security(self, data_assets):
"""
Deploy multi-layered security controls
"""
security_layers = {
'encryption_strategy': self._design_encryption_approach(),
'access_controls': self._implement_rbac_framework(),
'network_security': self._configure_network_protections(),
'application_security': self._harden_data_applications(),
'physical_security': self._ensure_physical_protections()
}
for asset in data_assets:
asset_security = self._apply_security_layers(asset, security_layers)
self.security_controls[asset['id']] = asset_security
return self.security_controls
def continuous_security_monitoring(self):
"""
Implement ongoing security surveillance
"""
monitoring_framework = {
'threat_detection': self._deploy_anomaly_detection(),
'access_monitoring': self._track_user_activities(),
'vulnerability_scanning': self._scan_for_weaknesses(),
'compliance_auditing': self._conduct_security_audits()
}
security_incidents = self._monitor_security_events(monitoring_framework)
# Automated response to security events
for incident in security_incidents:
self._trigger_incident_response(incident)
return security_incidents
def data_privacy_management(self, personal_data_assets):
"""
Ensure compliance with privacy regulations
"""
privacy_framework = {
'consent_management': self._manage_user_consents(),
'data_minimization': self._implement_minimization_principles(),
'purpose_limitation': self._enforce_usage_restrictions(),
'rights_fulfillment': self._facilitate_data_subject_requests()
}
privacy_compliance = {}
for data_asset in personal_data_assets:
compliance_status = self._assess_privacy_compliance(
data_asset, privacy_framework)
privacy_compliance[data_asset['id']] = compliance_status
return privacy_compliance
Encryption and Access Control Strategies
In modern data security, Encryption and Access Control are the twin pillars protecting information throughout its lifecycle. Encryption acts as the last line of defense, rendering data unreadable to unauthorized parties. This involves deploying a tiered strategy: highly sensitive data requires robust AES-256 encryption at rest, backed by Hardware Security Modules (HSMs) for key management, while all data in transit is shielded with TLS 1.3. The strategy must be dynamic, applying stronger algorithms to critical data to balance security with performance.
However, encryption alone is insufficient without rigorous Access Control. This governs who can see and use the data. The cornerstone is Role-Based Access Control (RBAC), which grants permissions based on a user’s job function, ensuring individuals only access data essential for their roles. This is strengthened by the principle of least privilege, minimizing each user’s access to the absolute minimum necessary. For the highest security environments, Mandatory Access Control (MAC) enforces system-wide policies that even owners cannot override. Together, these layered strategies create a robust defense, ensuring that even if data is intercepted or a system is breached, the information remains secure and accessible only to authorized personnel.
python
def implement_data_encryption_strategy(data_classification):
"""
Design appropriate encryption based on data sensitivity
"""
encryption_framework = {
'high_sensitivity': {
'encryption_at_rest': 'AES-256',
'encryption_in_transit': 'TLS_1.3',
'key_management': 'HSM_backed',
'access_logging': 'comprehensive'
},
'medium_sensitivity': {
'encryption_at_rest': 'AES-256',
'encryption_in_transit': 'TLS_1.2',
'key_management': 'cloud_kms',
'access_logging': 'standard'
},
'low_sensitivity': {
'encryption_at_rest': 'AES-128',
'encryption_in_transit': 'TLS_1.2',
'key_management': 'software_based',
'access_logging': 'basic'
}
}
encryption_implementation = {}
for classification, assets in data_classification.items():
encryption_config = encryption_framework.get(
classification, encryption_framework['low_sensitivity'])
encryption_implementation[classification] = {
'assets': assets,
'encryption_config': encryption_config,
'implementation_status': 'planned'
}
return encryption_implementation
Stage 6: Data Quality Management System
Continuous Quality Monitoring and Improvement
Data quality management must be an ongoing process throughout the Data lifecycle to maintain data reliability.
Quality Management Framework:
python
class DataQualityManager:
"""
Manage data quality throughout the lifecycle
"""
def __init__(self):
self.quality_metrics = {}
self.quality_thresholds = {
'completeness': 0.95,
'accuracy': 0.98,
'consistency': 0.97,
'timeliness': 0.99,
'validity': 0.96
}
def implement_quality_monitoring(self, data_assets):
"""
Continuous monitoring of data quality dimensions
"""
monitoring_system = {
'automated_checks': self._deploy_quality_checks(),
'quality_scorecards': self._generate_quality_reports(),
'alerting_mechanisms': self._setup_quality_alerts(),
'trend_analysis': self._analyze_quality_trends()
}
quality_results = {}
for asset in data_assets:
asset_quality = self._measure_quality_dimensions(asset)
quality_results[asset['id']] = asset_quality
# Trigger improvements for low quality
if asset_quality['overall_score'] < 0.9:
self._initiate_quality_improvement(asset, asset_quality)
return quality_results
def establish_quality_improvement_process(self):
"""
Systematic approach to quality enhancement
"""
improvement_framework = {
'root_cause_analysis': self._investigate_quality_issues(),
'corrective_actions': self._implement_quality_fixes(),
'preventive_measures': self._deploy_quality_preventions(),
'continuous_improvement': self._foster_quality_culture()
}
return improvement_framework
Data Quality Dimensions and Metrics
python
def define_quality_dimensions():
"""
Establish comprehensive quality measurement framework
"""
quality_dimensions = {
'completeness': {
'metric': 'percentage_of_populated_fields',
'threshold': 0.95,
'measurement_frequency': 'daily'
},
'accuracy': {
'metric': 'agreement_with_trusted_sources',
'threshold': 0.98,
'measurement_frequency': 'weekly'
},
'consistency': {
'metric': 'absence_of_conflicting_information',
'threshold': 0.97,
'measurement_frequency': 'daily'
},
'timeliness': {
'metric': 'data_freshness_against_requirements',
'threshold': 0.99,
'measurement_frequency': 'real_time'
},
'validity': {
'metric': 'conformance_to_business_rules',
'threshold': 0.96,
'measurement_frequency': 'continuous'
},
'uniqueness': {
'metric': 'absence_of_duplicate_records',
'threshold': 0.99,
'measurement_frequency': 'weekly'
}
}
return quality_dimensions
Stage 7: Data Governance and Compliance Framework
Establishing Effective Data Governance
Strong governance ensures consistent management and usage of data throughout the Data lifecycle.
Governance Implementation:
python
class DataGovernanceManager:
"""
Implement comprehensive data governance
"""
def establish_governance_framework(self, organizational_structure):
"""
Create data governance structure and processes
"""
governance_framework = {
'governance_bodies': {
'data_governance_council': self._form_governance_council(),
'data_stewardship_network': self._appoint_data_stewards(),
'data_quality_teams': self._establish_quality_teams()
},
'policies_and_standards': {
'data_management_policies': self._develop_management_policies(),
'data_quality_standards': self._set_quality_standards(),
'data_security_policies': self._define_security_requirements(),
'data_privacy_standards': self._establish_privacy_controls()
},
'processes_and_procedures': {
'data_classification_procedure': self._create_classification_process(),
'data_access_approval': self._implement_access_controls(),
'incident_management': self._develop_incident_procedures(),
'change_management': self._establish_change_controls()
}
}
return governance_framework
def implement_compliance_management(self, regulatory_requirements):
"""
Ensure ongoing regulatory compliance
"""
compliance_framework = {
'regulation_mapping': self._map_regulatory_requirements(),
'compliance_monitoring': self._implement_compliance_checks(),
'audit_preparation': self._maintain_audit_readiness(),
'reporting_obligations': self._fulfill_regulatory_reporting()
}
compliance_status = {}
for regulation in regulatory_requirements:
regulation_compliance = self._assess_compliance_status(
regulation, compliance_framework)
compliance_status[regulation['name']] = regulation_compliance
return compliance_status
Regulatory Compliance Automation
python
def automate_compliance_management(applicable_regulations):
"""
Implement automated compliance monitoring and reporting
"""
compliance_automation = {
'gdpr_compliance': {
'consent_management': automate_consent_tracking(),
'data_subject_requests': automate_request_fulfillment(),
'privacy_impact_assessments': automate_pia_process(),
'breach_notification': automate_breach_detection()
},
'ccpa_compliance': {
'consumer_rights': automate_rights_management(),
'data_mapping': automate_data_inventory(),
'opt_out_mechanisms': automate_preference_management()
},
'hipaa_compliance': {
'phi_protection': automate_phi_safeguards(),
'access_controls': automate_healthcare_access(),
'audit_trails': automate_compliance_logging()
}
}
implemented_controls = {}
for regulation in applicable_regulations:
if regulation in compliance_automation:
implemented_controls[regulation] = compliance_automation[regulation]
return {
'automated_controls': implemented_controls,
'compliance_coverage': calculate_compliance_coverage(implemented_controls),
'remaining_manual_processes': identify_manual_requirements()
}
Stage 8: Data Value Optimization and ROI Measurement
Maximizing Business Value from Data Assets
The ultimate goal of Data lifecycle optimization is to maximize the business value derived from data assets.
Value Measurement Framework:
python
class DataValueOptimizer:
"""
Measure and optimize data business value
"""
def calculate_data_roi(self, data_assets, business_context):
"""
Calculate return on investment for data initiatives
"""
roi_framework = {
'cost_tracking': self._track_data_related_costs(),
'benefit_quantification': self._quantify_business_benefits(),
'value_attribution': self._attribute_value_to_data(),
'performance_benchmarking': self._benchmark_against_industry()
}
roi_calculations = {}
for asset in data_assets:
asset_roi = self._compute_asset_roi(asset, roi_framework)
roi_calculations[asset['id']] = asset_roi
return roi_calculations
def optimize_data_monetization(self, data_assets):
"""
Identify and implement data monetization opportunities
"""
monetization_strategies = {
'direct_monetization': self._identify_direct_sales_opportunities(),
'indirect_monetization': self._find_operational_efficiency_gains(),
'strategic_monetization': self._discover_competitive_advantages(),
'innovative_monetization': self._explore_new_business_models()
}
monetization_opportunities = []
for strategy_type, strategy_method in monetization_strategies.items():
opportunities = strategy_method(data_assets)
monetization_opportunities.extend(opportunities)
return sorted(monetization_opportunities,
key=lambda x: x['estimated_value'], reverse=True)
def implement_data_value_tracking(self):
"""
Track data value throughout the lifecycle
"""
value_tracking_system = {
'value_metrics': self._define_value_measurements(),
'tracking_mechanisms': self._implement_value_monitoring(),
'reporting_framework': self._create_value_reporting(),
'improvement_initiatives': self._drive_value_enhancement()
}
return value_tracking_system
Performance Metrics and KPIs
python
def establish_data_lifecycle_kpis():
"""
Define key performance indicators for lifecycle management
"""
lifecycle_kpis = {
'data_quality_metrics': {
'overall_quality_score': 'target: >95%',
'data_completeness_rate': 'target: >98%',
'error_rate_reduction': 'target: <1%',
'user_satisfaction_score': 'target: >4.5/5'
},
'operational_efficiency': {
'data_processing_time': 'target: reduce by 30%',
'storage_cost_per_gb': 'target: reduce by 25%',
'manual_intervention_rate': 'target: <5%',
'automation_coverage': 'target: >90%'
},
'business_impact': {
'time_to_insight': 'target: reduce by 50%',
'data_driven_decisions': 'target: increase by 40%',
'revenue_attributed_to_data': 'target: increase by 25%',
'cost_savings_from_optimization': 'target: 20% reduction'
},
'security_and_compliance': {
'security_incident_rate': 'target: zero incidents',
'compliance_audit_scores': 'target: 100% pass rate',
'data_breach_prevention': 'target: 100% prevention',
'privacy_violation_incidents': 'target: zero violations'
}
}
return lifecycle_kpis
Implementation Roadmap and Best Practices
Phased Implementation Approach
Successful Data lifecycle optimization requires a structured, phased approach:
Phase 1: Foundation Establishment (Months 1-3)
- Conduct current state assessment
- Establish data governance framework
- Implement basic data quality controls
- Create data inventory and catalog
Phase 2: Core Capability Building (Months 4-9)
- Deploy data quality monitoring
- Implement security controls
- Establish data stewardship
- Automate basic data processes
Phase 3: Advanced Optimization (Months 10-18)
- Implement predictive quality management
- Deploy AI/ML for data optimization
- Establish continuous improvement processes
- Expand data monetization initiatives
Phase 4: Maturity and Innovation (Months 19+)
- Optimize based on performance data
- Innovate with new data capabilities
- Scale successful initiatives
- Drive cultural transformation
Critical Success Factors
- Executive Sponsorship: Strong leadership commitment and funding
- Cross-Functional Collaboration: Involvement from business and IT stakeholders
- Change Management: Addressing cultural and organizational barriers
- Technology Enablement: Appropriate tools and infrastructure
- Continuous Improvement: Ongoing measurement and optimization
- Skills Development: Training and capability building
- Communication Strategy: Clear messaging and stakeholder engagement
Conclusion: The Strategic Impact of Data Lifecycle Optimization
Data lifecycle optimization represents a fundamental shift in how organizations manage and leverage their most valuable asset—data. By implementing a comprehensive approach to Data lifecycle management, organizations can achieve remarkable improvements in data quality, security posture, regulatory compliance, and business value generation. The journey toward Data lifecycle excellence is not merely a technical initiative but a strategic transformation that touches every aspect of organizational operations.
The benefits of effective Data lifecycle management extend far beyond cost reduction and risk mitigation. Organizations that master their Data lifecycle gain competitive advantages through faster time-to-insight, improved decision-making quality, enhanced customer experiences, and innovative business models. The framework presented in this guide provides a roadmap for transforming data from a passive byproduct of business operations into an active, strategic asset that drives organizational success.
As data continues to grow in volume, variety, and velocity, the importance of Data lifecycle optimization will only increase. Organizations that proactively manage their Data lifecycle will be better positioned to navigate evolving regulatory landscapes, harness emerging technologies, and capitalize on new business opportunities. The investment in Data lifecycle optimization today lays the foundation for data-driven success tomorrow, ensuring that organizations can extract maximum value from their data assets while maintaining the highest standards of quality, security, and compliance throughout the entire data journey.