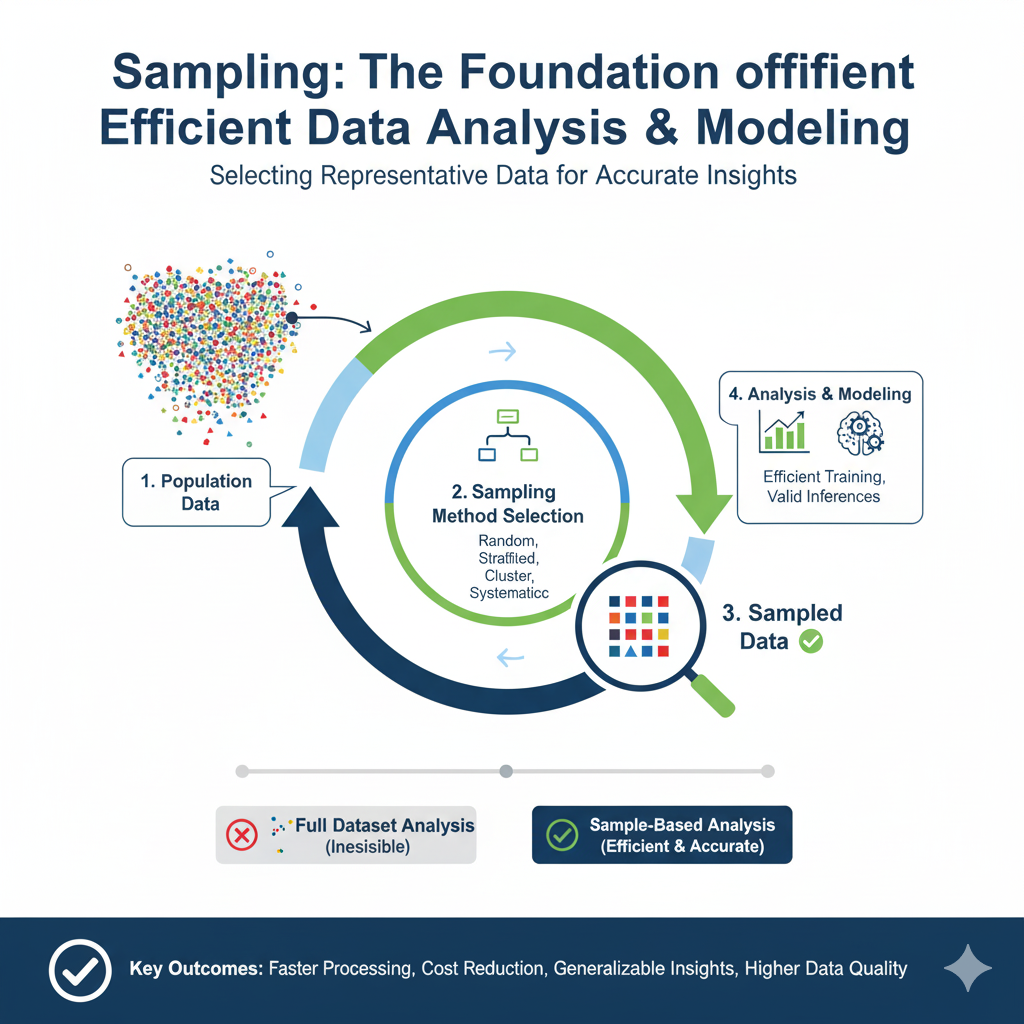
Top 10 Neural Network Architectures Every Data Scientist Should Know
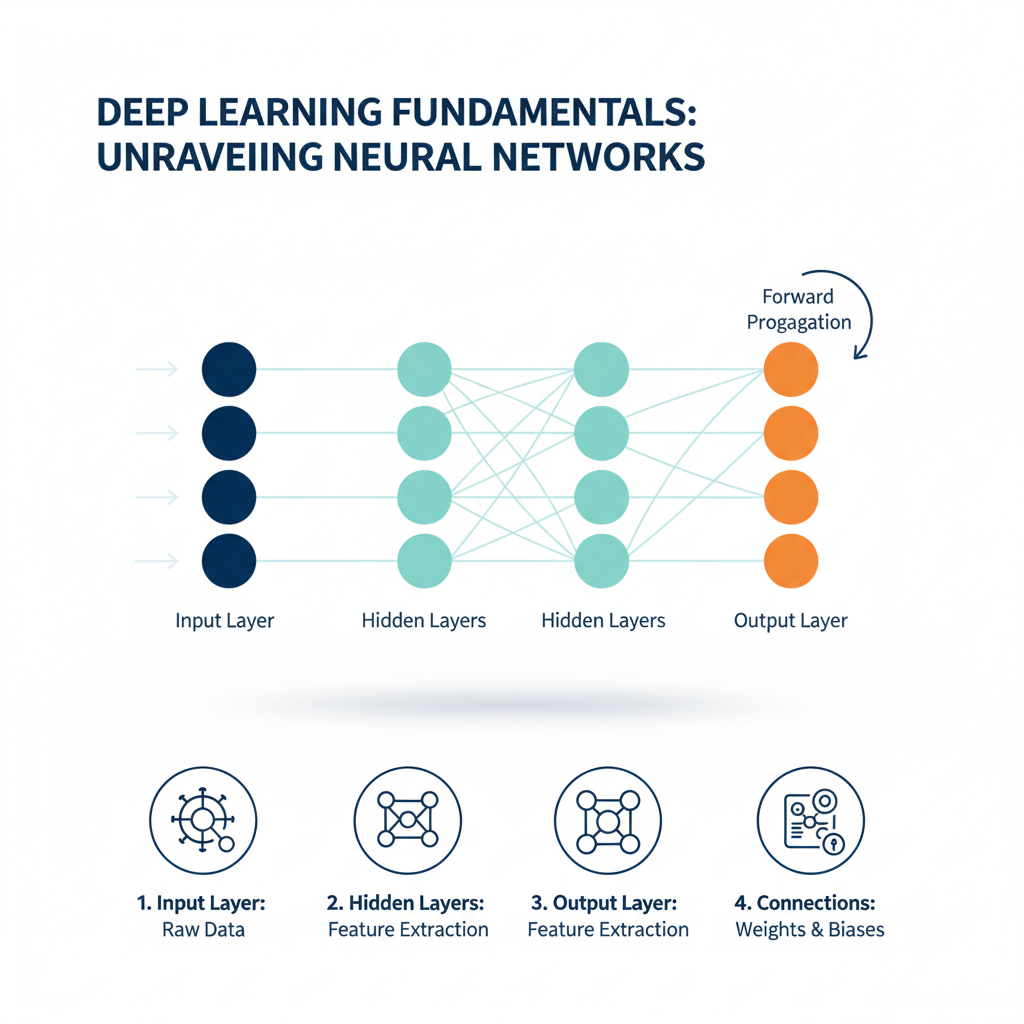
Introduction: The Architectural Revolution in Artificial Intelligence The field of artificial intelligence is undergoing a renaissance, largely driven by advances in a technology inspired by the human brain: the Neural Network. At its core, a Neural Network is a computational model composed of interconnected layers of nodes, or “neurons,” that can learn to recognize patterns and relationships in … Read more