Master embedding techniques in 2025: From Word2Vec to Transformers, CLIP, and Graph Neural Networks. Learn how to convert text, images, audio, and graphs into powerful vector representations for cutting-edge AI applications
Abstract
In the realm of artificial intelligence, the fundamental challenge is bridging the gap between the complex, unstructured world of human understanding and the rigid, numerical world of machine computation. The solution to this challenge is Embedding. An Embedding is a learned, dense, low-dimensional vector representation of discrete, high-dimensional data—be it words, images, categories, or graphs—that captures its semantic meaning in a continuous space. As we move through 2025.
the mastery of Embedding techniques is no longer a niche skill but a core competency for any data scientist working with deep learning. This article provides a deep dive into the top 10 Embedding techniques, from the foundational Word2Vec to the revolutionary context-aware transformers, equipping you with the knowledge to choose and apply the right method for any task.
1. The Foundational Concept: What is an Embedding?
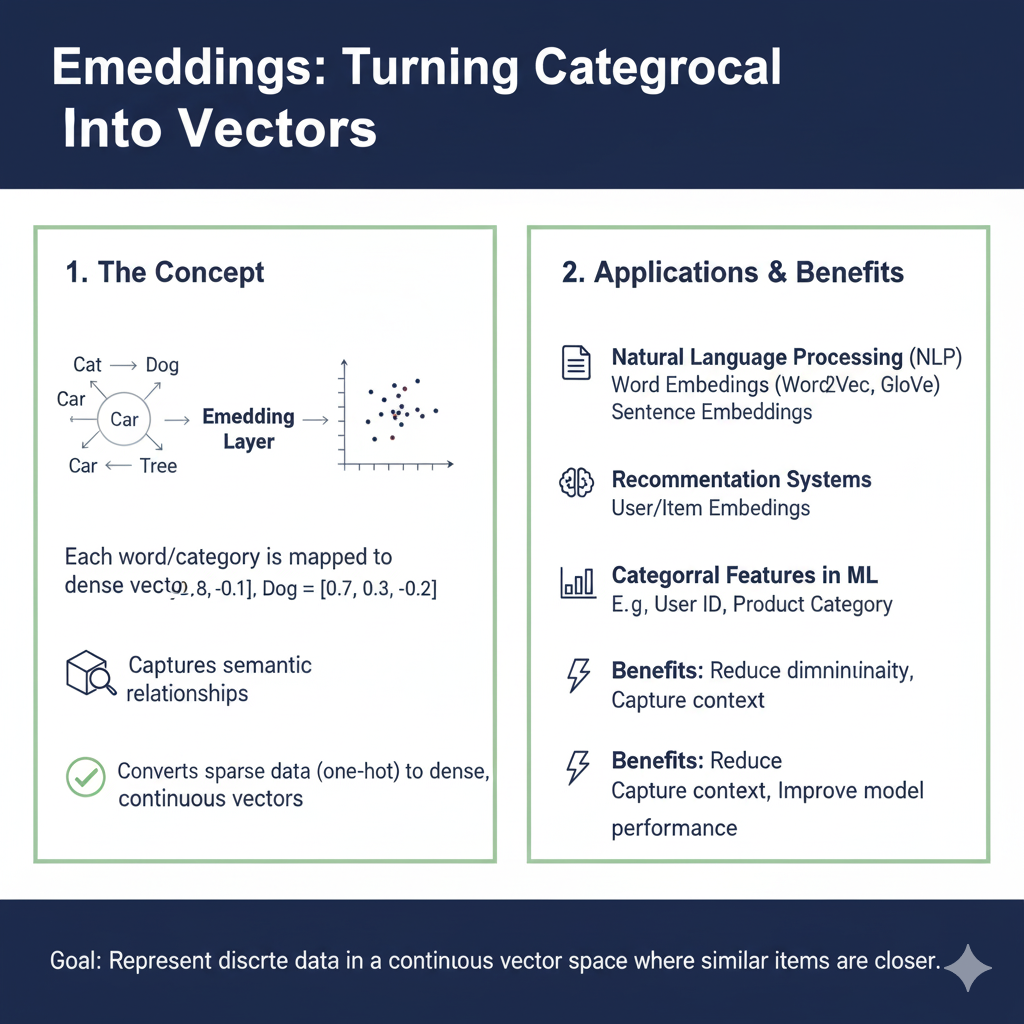
At its core, an Embedding is a form of representation learning. Instead of manually engineering features (like one-hot encoding), we allow a model to learn to represent data in a way that is optimal for a given task.
The Key Properties of a Good Embedding:
- Dimensionality Reduction: It compresses high-dimensional, sparse data (e.g., a one-hot vector of size 50,000 for a vocabulary) into a low-dimensional, dense vector (e.g., 300 dimensions).
- Semantic Meaningfulness: The geometric relationships in the embedding space reflect semantic relationships in the original data. The famous example is:
vector("King") - vector("Man") + vector("Woman") ≈ vector("Queen"). - Task-Specific Utility: The embeddings are learned to improve performance on a downstream task like classification, translation, or recommendation.
The following ten techniques represent the evolution and pinnacle of this powerful idea.
2. The Top 10 Embedding Techniques
2.1 Word2Vec: The Revolution Begins
Core Concept: Introduced by Google in 2013, Word2Vec is not a single algorithm but a family of models that learn word embeddings by leveraging a simple yet powerful idea: “a word is known by the company it keeps.” It uses a shallow neural network to learn word representations from large corpora of text.
How it Works:
- Continuous Bag-of-Words (CBOW): Predicts a target word given its surrounding context words. It’s faster and works well with frequent words.
- Skip-gram: Predicts the surrounding context words given a target word. It performs better with rare words and is generally preferred for larger datasets.
Key Strengths:
- Captures semantic and syntactic word relationships effectively.
- Highly efficient to train on large, unlabeled corpora.
- The foundational technique that popularized modern word embeddings.
Common Use Cases:
- Feature generation for classic ML models on text data.
- Initializing embeddings for more complex NLP models.
- Semantic search and document similarity.
2025 Relevance: While superseded for state-of-the-art tasks, its simplicity and efficiency make it a valuable tool for prototyping, educational purposes, and applications where computational resources are limited.
2.2 GloVe (Global Vectors for Word Representation)
Core Concept: Developed at Stanford, GloVe takes a different, more matrix factorization-oriented approach. While Word2Vec learns from local context windows, GloVe leverages global word-word co-occurrence statistics from the entire corpus.
How it Works:
It constructs a massive co-occurrence matrix X, where X_{ij} indicates how often word j appears in the context of word i. The model then learns embeddings such that the dot product of two word vectors equals the logarithm of their co-occurrence probability.
Key Strengths:
- Often outperforms Word2Vec on word analogy tasks as it captures global corpus statistics.
- Generally produces high-quality embeddings with strong performance.
Common Use Cases:
Similar to Word2Vec, but often chosen for its robust performance on a wider range of semantic tasks.
2025 Relevance: Like Word2Vec, it’s a foundational, static method. It serves as a strong baseline and is still widely used in academic benchmarks and production systems where context-awareness is not required.
2.3 Transformer-Based Embeddings (BERT, RoBERTa, etc.)
Core Concept: This represents a paradigm shift from static to contextualized embeddings. Models like BERT (Bidirectional Encoder Representations from Transformers) generate a unique embedding for a word based on its surrounding sentence. The word “bank” will have different embeddings in “river bank” and “financial bank.”
How it Works:
These models use the Transformer encoder architecture, which employs self-attention mechanisms to weigh the influence of all other words in a sentence when encoding a specific word. They are pre-trained on massive text corpora using objectives like Masked Language Modeling (MLM).
Key Strengths:
- Context-Awareness: The core advantage. Drastically improves performance on downstream NLP tasks.
- Bidirectional: Understands context from both the left and right of a word.
- Transfer Learning: Pre-trained models can be fine-tuned with minimal data for specific tasks.
Common Use Cases:
- Sentiment analysis, named entity recognition (NER), question answering.
- State-of-the-art performance on nearly all NLP benchmarks.
2025 Relevance: The undisputed standard for any serious NLP work in 2025. The ecosystem around models like BERT, DeBERTa, and their variants continues to dominate.
2.4 Sentence Transformers & SentenceBERT
Core Concept: While BERT is excellent for word- and sentence-level tasks, it is inefficient for deriving sentence-level embeddings (requiring complex workarounds like CLS pooling). Sentence Transformers (and the specific model SentenceBERT) modify the BERT architecture with siamese and triplet network structures to produce semantically meaningful sentence embeddings directly.
How it Works:
It fine-tunes BERT/RoBERTa on natural language inference (NLI) and other datasets with a contrastive learning objective. The goal is to make the cosine similarity between embeddings of semantically similar sentences high and dissimilar sentences low.
Key Strengths:
- Computationally efficient for sentence-level similarity tasks.
- Produces high-quality, fixed-length sentence embeddings.
- Enables scalable semantic search and clustering.
Common Use Cases:
- Semantic search (e.g., search engines, chatbots).
- Text clustering and paraphrase identification.
- Information retrieval and dense passage retrieval.
2025 Relevance: Absolutely critical for modern search, RAG (Retrieval-Augmented Generation) systems, and any application requiring comparing pieces of text at a level higher than a single word.
2.5 Image Embeddings (CNNs & Vision Transformers)
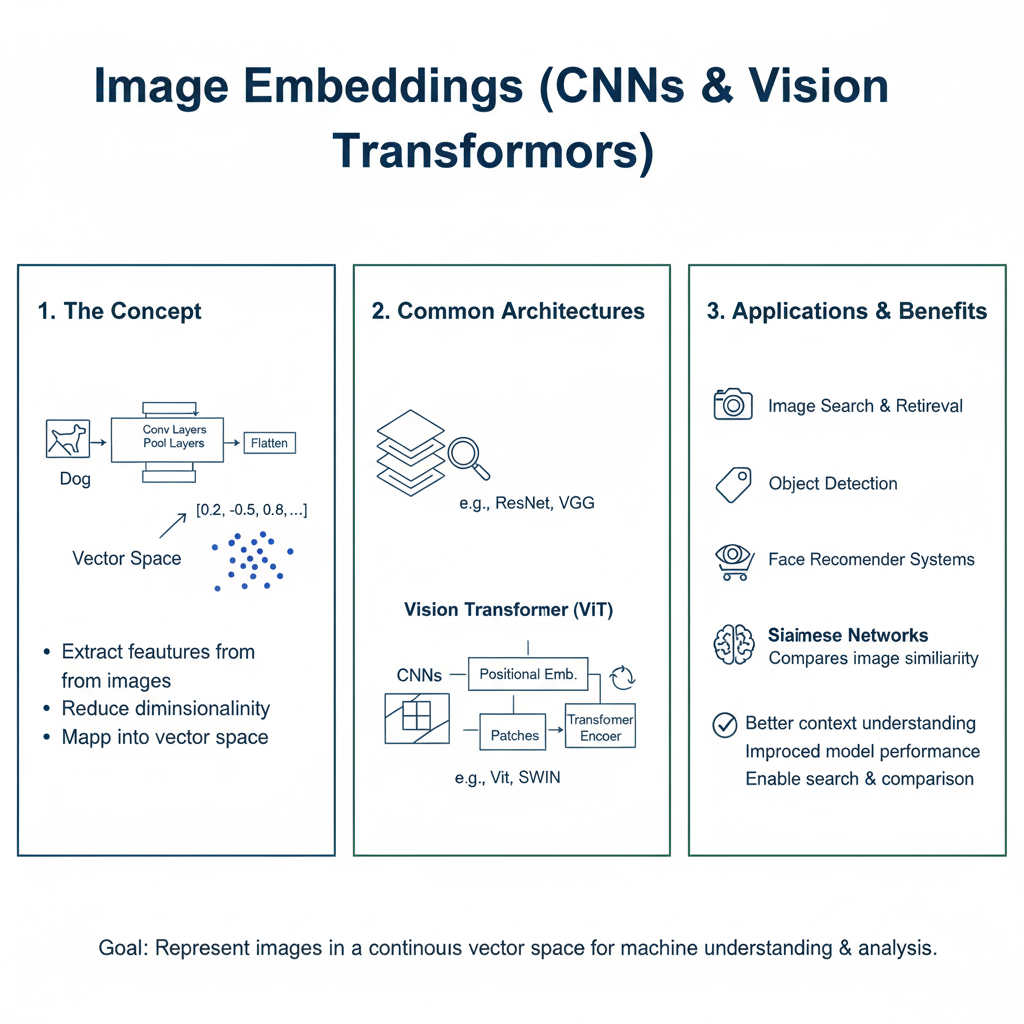
Core Concept: The principle of Embedding is not limited to text. Convolutional Neural Networks (CNNs) and, more recently, Vision Transformers (ViTs) learn to represent images as dense vectors in a high-dimensional space where geometric distance corresponds to visual and semantic similarity.
How it Works:
- CNNs: A pre-trained CNN (e.g., ResNet, EfficientNet) is used as a feature extractor. The activations from the final layer before the classification head are used as the image embedding.
- ViTs: An image is split into patches, which are treated similarly to tokens in NLP. A Transformer encoder then processes this sequence to produce a final [CLS] token embedding that represents the entire image.
Key Strengths:
- Powerful semantic understanding of visual content.
- Pre-trained models on ImageNet provide robust, off-the-shelf feature extractors.
Common Use Cases:
- Visual product search (“search with an image”).
- Image clustering and deduplication.
- Content-based image recommendation.
2025 Relevance: The backbone of computer vision. ViT-based embeddings are increasingly becoming the new standard, offering superior performance and scalability.
2.6 Category Embeddings for Tabular Data
Core Concept: Categorical variables in tabular data are often encoded using one-hot encoding, which is inefficient and loses any potential relationship between categories. Embedding layers can be used to learn meaningful, dense representations for each category level.
How it Works:
In a neural network model for tabular data, an Embedding layer is created for each high-cardinality categorical feature. The layer maps each unique category to a dense vector. These embeddings are then concatenated with the continuous features and fed into the rest of the network.
Key Strengths:
- Automatically discovers latent relationships between categories (e.g., “San Francisco” and “New York” might be closer than “San Francisco” and “a small town”).
- More parameter-efficient and powerful than one-hot encoding.
Common Use Cases:
- Any deep learning model on structured data (e.g., risk prediction, recommendation systems).
- Handling high-cardinality features like user IDs, product SKUs, and zip codes.
2025 Relevance: A standard and highly effective technique in the toolkit of any data scientist working with deep learning for tabular data, as popularized by libraries like PyTorch Tabular and Fast.ai.
2.7 Graph Embeddings (Node2Vec, GraphSAGE)
Core Concept: How can we represent nodes, edges, or entire subgraphs in a network? Graph Embedding techniques learn to map the structural information of a graph into a continuous vector space.
How it Works:
- Node2Vec: Uses biased random walks to explore a node’s neighborhood and then applies a Skip-gram-like model to learn embeddings that preserve network topology.
- GraphSAGE (SAmple and aggreGatE): An inductive method that learns an aggregation function (e.g., mean, LSTM) from a node’s local neighborhood. This allows it to generate embeddings for unseen nodes.
Key Strengths:
- Captures complex topological features like community structure and node roles.
- Enables machine learning on graph data (e.g., node classification, link prediction).
Common Use Cases:
- Social network analysis (friend recommendation, influencer detection).
- Fraud detection in transaction networks.
- Drug discovery and bioinformatics.
2025 Relevance: With the rise of relational data and knowledge graphs, graph embeddings are becoming increasingly vital for powering recommendation systems and complex network analysis.
2.8 Audio Embeddings (Wav2Vec 2.0, Whisper)
Core Concept: Similar to images and text, audio signals (speech, sounds) can be converted into dense vector representations that capture phonetic, speaker, and semantic information.
How it Works:
- Wav2Vec 2.0: A self-supervised model that learns powerful speech representations from raw audio by solving a contrastive task over masked latent speech representations.
- OpenAI’s Whisper: A Transformer model trained on a massive dataset of diverse audio, which learns embeddings that are robust to transcription, translation, and speaker identification.
Key Strengths:
- Eliminates the need for hand-crafted audio features like MFCCs in many cases.
- Provides state-of-the-art performance for speech recognition and audio classification.
Common Use Cases:
- Automatic Speech Recognition (ASR).
- Speaker identification and emotion detection.
- Audio-based search and content moderation.
2025 Relevance: Essential for the booming field of voice-enabled AI and audio analytics. Self-supervised models like Wav2Vec 2.0 have democratized high-quality speech processing.
2.9 Cross-Modal & Multimodal Embeddings (CLIP)
Core Concept: This is the frontier of Embedding technology. Cross-modal models learn a shared embedding space for different data modalities (e.g., text and images), allowing for direct comparison and translation between them.
How it Works:
- CLIP (Contrastive Language-Image Pre-training): OpenAI’s CLIP is trained on hundreds of millions of image-text pairs. It uses two encoders (image and text) and a contrastive learning objective to ensure that the embedding of an image is close to the embedding of its corresponding text description.
Key Strengths:
- Enables zero-shot image classification (classifying images into categories it was never explicitly trained on).
- Powers natural language-based image search and generation.
Common Use Cases:
- Zero-shot learning and image retrieval (“find me a picture of a red car on a mountain”).
- The foundational model for text-to-image generators like DALL-E and Stable Diffusion.
2025 Relevance: One of the most important advancements in AI. CLIP-style embeddings are the backbone of the generative AI revolution and a key component for building more general-purpose, flexible AI systems.
2.10 Dynamic & Time Series Embeddings (RNNs, Transformers)
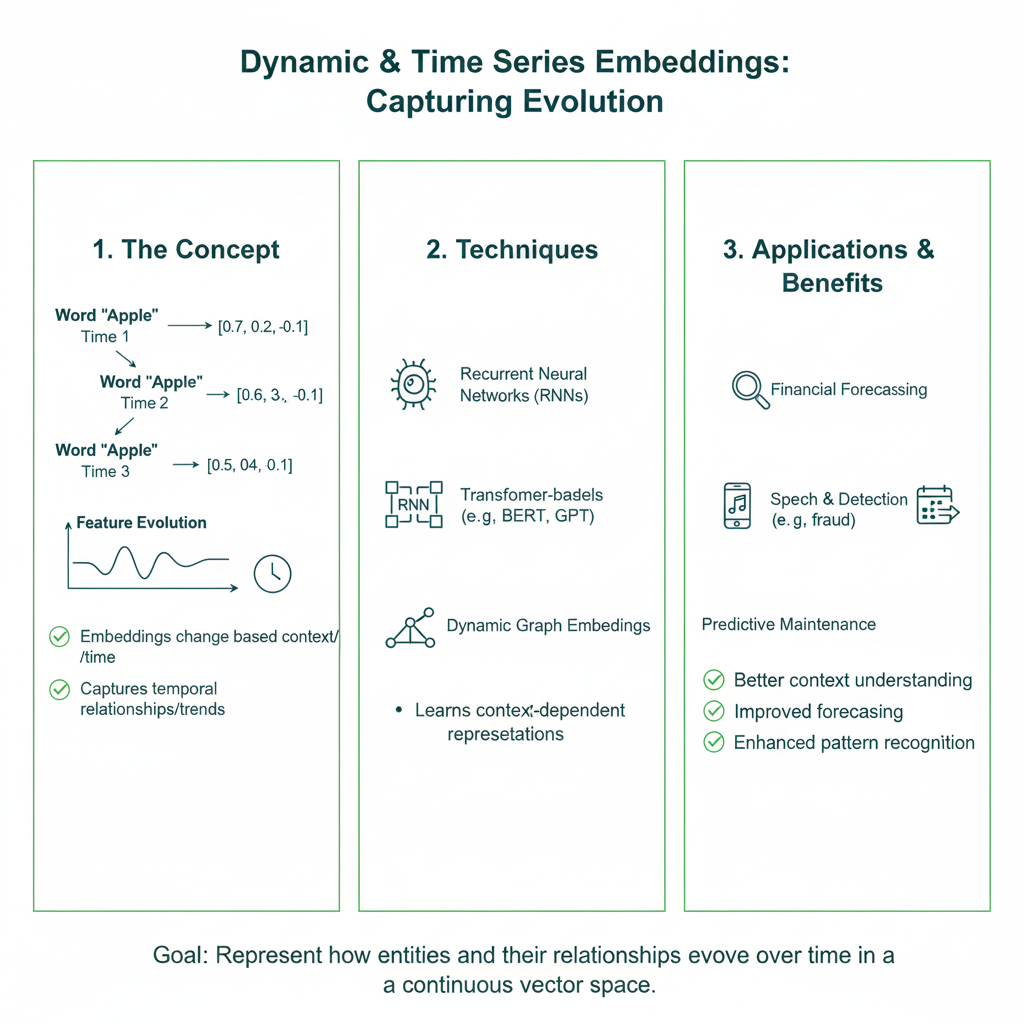
Core Concept: Sequential data, such as time series sensor readings or stock prices, has a temporal dependency. Embedding here involves creating a representation for a whole sequence or a specific point in time that encapsulates its historical context.
How it Works:
- RNN/LSTM/GRU: The final hidden state of the RNN after processing an entire sequence is often used as the sequence embedding.
- Transformers for Time Series: Similar to NLP, a Transformer encoder can process a sequence of time steps, using positional encoding to account for order, and produce a contextualized embedding for each time step or the whole series.
Key Strengths:
- Captures temporal patterns, trends, and seasonality.
- Can handle variable-length sequences.
Common Use Cases:
- Anomaly detection in sensor data.
- Financial market forecasting.
- Human activity recognition from motion sensor data.
2025 Relevance: Critical for the Internet of Things (IoT), finance, and healthcare, where sequential data is ubiquitous. Transformer-based models are setting new standards in this domain.
3. A Practical Guide: Choosing the Right Embedding in 2025
With this arsenal of techniques, how do you choose? Here is a decision framework:
| Your Data Type | Primary Task | Recommended Embedding Technique |
|---|---|---|
| Text (Word Level) | Semantic Similarity, Baseline Model | Word2Vec or GloVe |
| Text (Word Level) | State-of-the-Art NLP (NER, QA) | BERT or similar Transformer |
| Text (Sentence/Doc) | Semantic Search, Clustering, RAG | Sentence Transformers |
| Image | Visual Search, Feature Extraction | ViT or CNN (ResNet) |
| Tabular Data | Handling Categorical Variables | Category Embeddings |
| Network/Graph | Node Classification, Link Prediction | GraphSAGE or Node2Vec |
| Audio/Speech | Speech Recognition, Sound Classification | Wav2Vec 2.0 or Whisper |
| Image + Text | Cross-Modal Search, Zero-Shot Learning | CLIP |
| Time Series | Forecasting, Anomaly Detection | Transformer or LSTM |
Implementation Tips for 2025:
- Leverage Pre-trained Models: Never start from scratch for text, image, or audio. Use libraries like
sentence-transformers,transformers(Hugging Face), and PyTorch Image Models (timm). - Fine-tune for Your Domain: Pre-trained embeddings are powerful, but fine-tuning them on your specific dataset almost always yields significant improvements.
- Monitor Embedding Drift: In production, the statistical properties of your data can change over time, leading to “embedding drift.” Implement monitoring to detect this and retrain your models periodically.
4. The Future of Embeddings
The field of Embedding is rapidly evolving. Key trends for 2025 and beyond include:
- Unified Multimodal Models: The line between modalities will continue to blur. Models like OpenAI’s GPT-4V (Vision) are steps towards a single, giant embedding space for all data types.
- Foundational Models and In-Context Learning: The concept of a static embedding is being challenged by large language models that can create dynamic, task-specific representations based on a given prompt or context.
- Self-Supervised Learning (SSL): The paradigm of learning embeddings without human-labeled data (as seen in Wav2Vec 2.0 and BERT) will become the standard across all modalities, reducing dependency on costly annotation.
5. Emerging Frontiers and Implementation Strategies
The landscape of representation learning continues to evolve at a rapid pace, with several new paradigms beginning to reshape how we think about vector representations. One significant shift is the movement toward unified architectures that can handle multiple data types within a single model framework. These systems learn a shared semantic space where text, images, audio, and other modalities can be directly compared and combined, enabling truly multimodal reasoning capabilities that were previously impossible.
Another frontier involves the development of more efficient and scalable approaches. As models grow larger and datasets expand, techniques for compressing these representations without sacrificing performance become increasingly valuable. Methods like product quantization, hashing techniques, and knowledge distillation are being refined to make powerful representations practical for resource-constrained environments, including edge devices and real-time applications.
The practical implementation of these technologies requires careful consideration of several factors. Data quality and volume remain paramount—even the most sophisticated approach will underperform with inadequate or noisy training data. The choice between using pre-trained representations versus training custom ones depends heavily on domain specificity and available computational resources. For most applications, starting with established pre-trained models and fine-tuning them on domain-specific data provides the best balance of performance and efficiency.
Monitoring and maintenance present ongoing challenges in production systems. Representations can become stale as data distributions shift over time, requiring robust pipelines for detecting concept drift and updating models accordingly. Additionally, considerations around fairness, bias, and interpretability are becoming increasingly important, necessitating tools and methodologies for auditing and understanding what information these vectors actually capture.
Looking forward, the integration of symbolic reasoning with distributed representations appears particularly promising. By combining the robustness and generalization capabilities of learned vectors with the precision and explicability of symbolic approaches, we may overcome current limitations in reasoning and knowledge representation. This hybrid approach could enable systems that not only recognize patterns but also understand and manipulate abstract concepts in ways that mirror human cognitive processes more closely.
. Conclusion
From representing a single word to encapsulating the meaning of an entire image or a complex graph, Embedding techniques are the fundamental building blocks of modern AI. They are the translators that convert our messy, unstructured reality into a language that machines can not only understand but also reason with. For the data scientist in 2025, a deep, practical understanding of these top 10 Embedding techniques is not optional—it is essential for building the intelligent, robust, and multimodal systems that will define the next decade of innovation. By strategically selecting and applying the right Embedding method, you unlock the true potential of your data.