Master data pipeline automation in 2025 with best practices for speed and scalability. Learn orchestration patterns, performance optimization, and emerging trends for building reliable, efficient data pipelines
Introduction: The Evolution of Data Pipelines in the Modern Data Stack
Data pipelines have evolved from simple ETL (Extract, Transform, Load) scripts to sophisticated, automated systems that form the circulatory system of modern data-driven organizations. In 2025, the landscape of data pipelines has been transformed by cloud-native architectures, real-time processing requirements, and the exponential growth of data volume and variety. The global data pipeline market, valued at $6.9 billion in 2022, is projected to reach $18.9 billion by 2027, reflecting the critical role these systems play in enabling data-driven decision-making across industries.
The modern data pipelines ecosystem encompasses a complex interplay of technologies, including cloud data warehouses, stream processing frameworks, workflow orchestration platforms, and data quality monitoring tools. What distinguishes 2025’s approach to data pipelines is the shift from manually managed, batch-oriented processes to fully automated, intelligent systems that can adapt to changing data patterns, self-heal from failures, and optimize performance dynamically. This evolution has been driven by several converging trends: the maturation of cloud data platforms, the standardization of containerization and orchestration, the rise of data mesh architectures, and increasing regulatory requirements for data governance and lineage.
This comprehensive guide explores the best practices for building automated data pipelines that deliver both speed and scalability in 2025’s demanding data environment. We’ll examine architectural patterns, technology selection criteria, implementation strategies, and operational considerations that separate high-performing data pipelines from those that become bottlenecks to organizational agility. Whether you’re building new data pipelines from scratch or modernizing legacy systems, understanding these principles is essential for creating data infrastructure that supports rather than constrains business innovation.
Foundational Principles of Modern Data Pipeline Design

The Four Pillars of Effective Data Pipelines
Reliability and Resilience form the non-negotiable foundation of production-grade data pipelines. In 2025, reliability extends beyond simple error handling to encompass comprehensive fault tolerance, graceful degradation, and automated recovery mechanisms. Modern data pipelines must be designed to withstand component failures, network interruptions, data quality issues, and schema changes without requiring manual intervention. This involves implementing idempotent operations that can be safely retried, checkpointing to track progress through long-running processes, and circuit breakers that prevent cascading failures. Advanced monitoring and alerting systems provide visibility into pipeline health, while automated rollback mechanisms ensure that failed deployments don’t compromise data integrity.
Scalability and Performance have become increasingly critical as data volumes continue to grow exponentially. Modern data pipelines must scale both horizontally (adding more processing nodes) and vertically (increasing resource allocation) to handle fluctuating workloads efficiently. The key to achieving scalability lies in designing stateless processing components, implementing effective partitioning strategies, and leveraging elastic cloud resources that can expand and contract based on demand. Performance optimization involves not just raw processing speed but also minimizing end-to-end latency, especially for real-time use cases. Techniques like data compression, columnar storage formats, and intelligent caching contribute to both scalability and performance by reducing I/O overhead and network transfer times.
Maintainability and Evolvability address the long-term sustainability of data pipelines as business requirements change and technologies evolve. Maintainable pipelines feature modular design with clear separation of concerns, comprehensive documentation, and standardized coding practices that enable multiple team members to collaborate effectively. Evolvability requires designing data pipelines with change in mind—using schema evolution techniques to handle structural changes in data, implementing feature flags for controlled rollout of new functionality, and maintaining backward compatibility to support gradual migration. Version control for pipeline definitions, infrastructure-as-code practices, and automated testing frameworks all contribute to maintainability by ensuring that changes can be made safely and consistently.
Security and Compliance have risen to paramount importance in an era of increasing data privacy regulations and cybersecurity threats. Modern data pipelines must incorporate security at every layer, from encryption of data in transit and at rest to fine-grained access controls governing who can read, write, or modify pipeline components. Compliance requirements drive the need for comprehensive audit trails, data lineage tracking, and data retention policies that can be automatically enforced. In regulated industries, data pipelines must support data sovereignty requirements by ensuring that processing occurs in approved geographic regions and that cross-border data transfers comply with local regulations. Privacy-enhancing technologies like differential privacy and homomorphic encryption are increasingly integrated into data pipelines to enable analytics while protecting sensitive information.
Architectural Patterns for Modern Data Pipelines
Lambda and Kappa Architectures represent two foundational approaches to building data pipelines that handle both batch and real-time processing requirements. The Lambda architecture maintains separate batch and speed layers that serve different latency requirements, with a serving layer that presents a unified view of the results. While this approach ensures comprehensive data processing, it introduces complexity through duplicated logic and the challenge of maintaining consistency between layers. The Kappa architecture simplifies this by using a single stream processing layer for all data, treating batch processing as a special case of stream processing with larger time windows. In 2025, the trend has shifted toward Kappa-inspired approaches using modern stream processing frameworks that can handle both real-time and historical data efficiently.
Data Mesh and Federated Governance represent a paradigm shift in how organizations structure their data pipelines and data ownership. Rather than centralized data teams building and maintaining all pipelines, the data mesh approach distributes responsibility to domain-oriented teams who own their data products end-to-end. This decentralization changes the nature of data pipelines from monolithic systems to interconnected networks of specialized pipelines that expose data as products. Federated governance ensures consistency and interoperability through global standards while allowing domain teams autonomy in implementation. This pattern improves scalability by enabling parallel development and reduces bottlenecks that occur when central teams become overwhelmed with requests.
Event-Driven Architectures have become the standard for building responsive, decoupled data pipelines that can react to business events in real time. Instead of polling for changes or running on fixed schedules, event-driven data pipelines respond to events published by source systems, enabling near-instantaneous data availability for downstream consumers. This approach reduces latency, improves resource utilization by processing data only when it changes, and creates more resilient systems through loose coupling between components. Modern message brokers and event streaming platforms provide the foundation for event-driven data pipelines, with features like exactly-once processing, dead-letter queues, and schema registries ensuring reliability and data quality.
Technology Stack Selection for 2025 Data Pipelines

Orchestration and Workflow Management
Apache Airflow has matured into the de facto standard for orchestrating complex data pipelines, with its DAG (Directed Acyclic Graph) based approach providing flexibility, visibility, and dependency management. In 2025, Airflow’s ecosystem has expanded to include native integrations with major cloud platforms, enhanced security features, and improved scalability through executors like KubernetesExecutor that can dynamically allocate resources. Best practices for Airflow implementation include designing idempotent tasks, implementing proper retry logic with exponential backoff, using XComs sparingly for inter-task communication, and leveraging the TaskFlow API for Pythonic pipeline definitions. The key to effective Airflow usage lies in treating DAGs as production code—applying software engineering practices like version control, testing, and code review.
Prefect and Dagster represent the next generation of workflow orchestration tools that address some of Airflow’s limitations, particularly around testing, development experience, and data awareness. Prefect’s hybrid execution model allows pipelines to run anywhere while providing centralized observability, while its concept of “flows” and “tasks” with automatic dependency management simplifies pipeline construction. Dagster takes a data-centric approach, modeling computations and data dependencies together and providing rich development tools for testing and debugging. Both platforms offer stronger typing, better testing support, and more intuitive interfaces than first-generation orchestration tools, making them attractive choices for new data pipelines in 2025.
Cloud-Native Orchestration Services like AWS Step Functions, Azure Data Factory, and Google Cloud Composer provide managed alternatives to self-hosted orchestration platforms. These services reduce operational overhead through automatic scaling, built-in monitoring, and seamless integration with other cloud services. The tradeoff comes in reduced flexibility and potential vendor lock-in, though abstraction layers like the Cloud Native Computing Foundation’s Workflow API aim to provide portability across cloud providers. When evaluating cloud-native orchestration, consider factors like integration with existing infrastructure, cost predictability, and the ability to handle both cloud and on-premises data sources.
Processing Frameworks and Execution Engines
Apache Spark continues to dominate the batch processing landscape, with its unified engine for large-scale data processing, SQL, streaming, and machine learning. Spark 3.0+ introduced significant performance improvements through adaptive query execution, dynamic partition pruning, and enhanced Python support through the pandas API. For data pipelines requiring complex transformations on large datasets, Spark provides unparalleled scalability and performance, especially when paired with optimized storage formats like Delta Lake, Iceberg, or Hudi that add ACID transactions and time travel capabilities. The key to effective Spark usage lies in understanding partitioning strategies, memory management, and the Catalyst optimizer’s behavior to avoid common performance pitfalls.
Stream Processing Platforms like Apache Flink, Kafka Streams, and ksqlDB have matured to handle the real-time component of modern data pipelines. Flink’s true streaming model with sophisticated state management and exactly-once processing semantics makes it ideal for complex event processing and real-time analytics. Kafka Streams provides a lighter-weight approach for applications already using Kafka, while ksqlDB enables stream processing using familiar SQL syntax. The selection criteria for stream processing platforms include latency requirements, state management needs, integration with existing infrastructure, and operational complexity. In 2025, the trend is toward managed streaming services that reduce the operational burden of maintaining complex streaming infrastructure.
Serverless and Containerized Processing represents the convergence of two powerful trends in data pipelines execution. Serverless platforms like AWS Lambda, Google Cloud Functions, and Azure Functions enable event-driven processing without managing servers, automatically scaling from zero to handle peak loads. Containerization with Kubernetes provides portability and resource isolation, with frameworks like Spark on Kubernetes enabling consistent deployment across environments. The emerging pattern involves using serverless functions for lightweight, event-driven tasks and containerized processing for heavy-weight batch jobs, with orchestration platforms managing the coordination between these different execution models.
Implementation Best Practices for Automated Data Pipelines
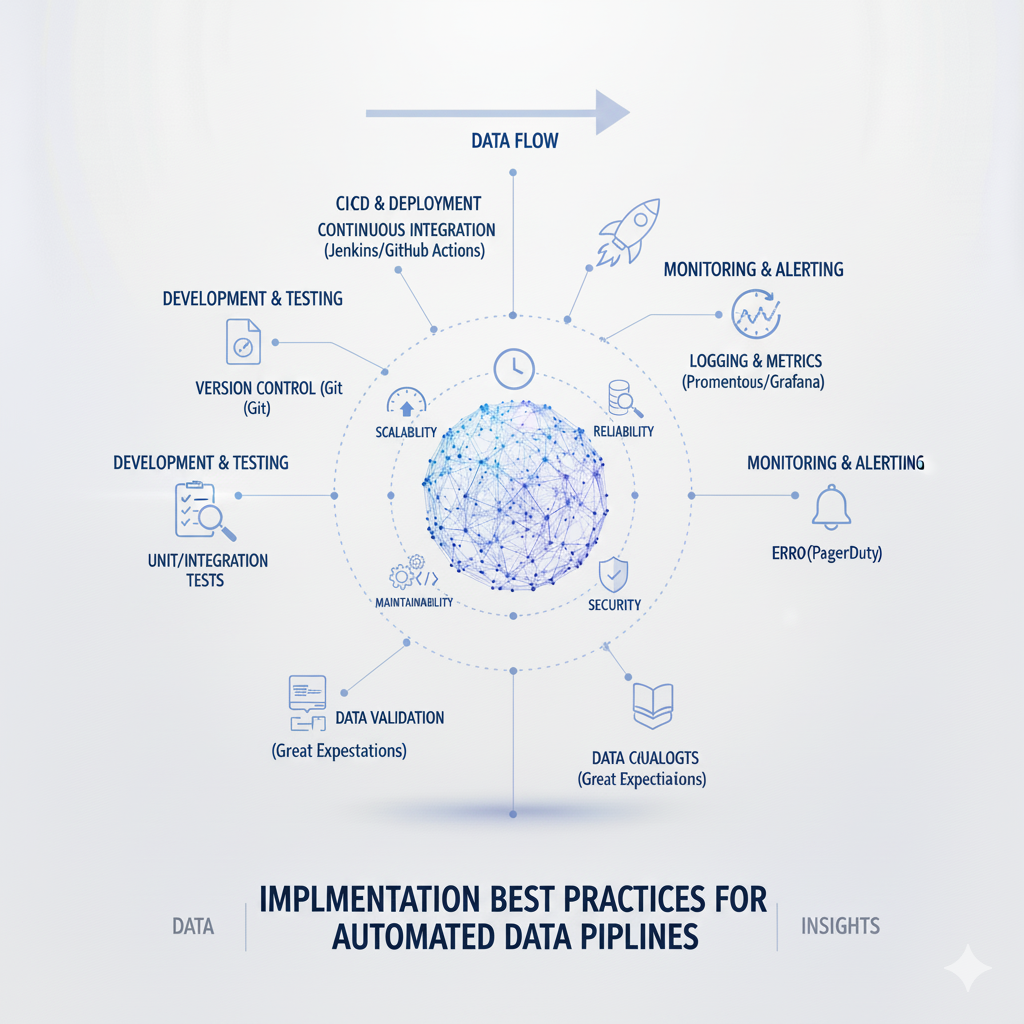
Pipeline Development and Deployment
Infrastructure as Code (IaC) has become the standard practice for managing data pipelines infrastructure, enabling reproducible environments, version control for infrastructure, and automated deployment pipelines. Tools like Terraform, Pulumi, and AWS CloudFormation allow teams to define their data infrastructure—including storage, compute resources, networking, and security configurations—in declarative code that can be versioned, reviewed, and tested alongside application code. Best practices for IaC in data pipelines include modularizing configurations for different environments, implementing policy-as-code to enforce security and compliance requirements, and using remote state management to coordinate changes across teams. The goal is to treat infrastructure with the same discipline as software, with automated testing, continuous integration, and controlled deployment processes.
CI/CD for Data Pipelines extends software engineering practices to the development and deployment of data pipelines, enabling faster iteration while maintaining quality and reliability. A robust CI/CD pipeline for data pipelines includes stages for linting and static analysis, unit testing of transformation logic, integration testing with sample datasets, and automated deployment to staging and production environments. Techniques like blue-green deployment or canary releases allow new pipeline versions to be tested with a subset of data before full rollout, reducing the impact of potential issues. Data-specific considerations in CI/CD include testing with representative data volumes, validating data quality expectations, and ensuring backward compatibility for schema changes.
Environment Management and Data Isolation present unique challenges for data pipelines compared to traditional software applications. While code can be tested in isolation, data pipelines inherently depend on data that may be too large, sensitive, or dynamic to copy easily across environments. Strategies for addressing this challenge include using data virtualization to provide isolated views of shared datasets, generating synthetic data that preserves statistical properties without exposing sensitive information, and implementing data masking techniques that obfuscate personally identifiable information while maintaining referential integrity. The key is to balance the need for realistic testing with practical constraints around data volume, privacy, and cost.
Data Quality and Reliability Engineering
Automated Data Quality Monitoring has evolved from simple validation checks to comprehensive quality frameworks that continuously assess data across multiple dimensions. Modern data pipelines incorporate quality checks at multiple stages: schema validation at ingestion, statistical profiling during processing, and business rule validation before delivering data to consumers. Tools like Great Expectations, Deequ, and Soda SQL enable declarative definition of data quality expectations that can be automatically enforced. Advanced quality monitoring includes anomaly detection that identifies unusual patterns in data distributions, data freshness monitoring that alerts when expected updates don’t arrive, and drift detection that catches gradual changes in data characteristics that might indicate underlying issues.
Error Handling and Recovery Patterns determine how data pipelines respond to the inevitable failures that occur in production systems. The most effective approaches implement graduated responses based on failure severity: automatic retries with exponential backoff for transient issues, dead-letter queues for records that cannot be processed after multiple attempts, and circuit breakers that temporarily disable components experiencing repeated failures. For more significant issues, automated rollback mechanisms can restore previous known-good states, while comprehensive logging and alerting ensure that human intervention occurs when needed. The goal is to minimize manual intervention for common failure scenarios while ensuring that unusual problems receive appropriate attention.
Data Lineage and Observability provide the visibility needed to understand, debug, and trust data pipelines in complex environments. Data lineage tools automatically track the flow of data from source to consumption, enabling impact analysis for proposed changes, root cause analysis when data issues arise, and compliance reporting for regulatory requirements. Observability extends beyond traditional monitoring to include distributed tracing that follows individual records through processing steps, metrics that capture business-level indicators of data health, and structured logging that facilitates automated analysis. Together, these capabilities create a comprehensive understanding of data pipelines behavior that supports both operational excellence and continuous improvement.
Performance Optimization Techniques
Processing Optimization Strategies
Parallelism and Partitioning represent the most powerful levers for optimizing data pipelines performance. Effective partitioning strategies align with the natural access patterns of the data—time-based partitioning for chronological data, key-based partitioning for entity-centric access, and geographic partitioning for location-aware applications. The goal is to maximize data locality while enabling parallel processing. Modern data pipelines implement dynamic partitioning that adapts to changing data distributions, with frameworks like Spark automatically determining optimal partition sizes based on data characteristics. For maximum performance, partitioning should be considered at multiple levels: input data organization, in-memory processing distribution, and output storage structure.
Memory Management and Caching significantly impact data pipelines performance, especially for iterative processing or operations that require multiple passes over the same data. Techniques like broadcast joins for small lookup tables, selective column pruning to reduce memory footprint, and spill-to-disk mechanisms for operations that exceed available memory help maintain performance across varying data sizes. Intelligent caching strategies identify frequently accessed datasets and keep them in memory or fast storage, with eviction policies that prioritize the most valuable data. The emergence of persistent memory technologies provides new opportunities for caching large datasets with near-memory speed while maintaining persistence across restarts.
Query Optimization and Execution Planning have become increasingly sophisticated in modern processing engines. Spark’s Catalyst optimizer uses rule-based and cost-based optimization to transform logical query plans into efficient physical execution plans, while Presto’s Velox execution engine provides vectorized processing that maximizes CPU efficiency. Understanding how these optimizers work enables data pipelines developers to write code that takes full advantage of the underlying engine capabilities. Best practices include using appropriate join strategies based on data size and distribution, avoiding unnecessary data shuffles, and leveraging predicate pushdown to filter data as early as possible in the processing pipeline.
Storage and I/O Optimization
Columnar Storage Formats like Parquet, ORC, and Avro have become the standard for analytical data pipelines due to their compression efficiency and query performance characteristics. These formats enable predicate pushdown, where query engines can skip reading irrelevant data based on statistics stored in file metadata, and column pruning, where only the columns needed for a particular operation are read from storage. Advanced features like dictionary encoding, run-length encoding, and bloom filters further improve performance for specific data patterns. The selection of storage format involves tradeoffs between write performance, read performance, compression ratio, and compatibility with different processing engines.
Data Compression Techniques reduce storage costs and I/O overhead, with different algorithms optimized for different data types. General-purpose compression like Snappy and LZ4 provide fast compression and decompression suitable for intermediate data, while more aggressive algorithms like Zstandard and Brotli offer better compression ratios for archival storage. For numerical data, specialized encoding like Delta encoding for monotonically increasing values or Gorilla compression for time-series data can achieve significantly better results than general-purpose algorithms. The key is to match compression strategy to data characteristics and access patterns, considering the CPU cost of compression against the I/O savings.
Intelligent Caching and Tiered Storage optimize data placement across different storage media based on access patterns. Hot data that’s frequently accessed resides in fast storage like SSDs or memory, while cold data moves to cheaper object storage. Automated tiering policies based on access frequency, modification time, or business rules ensure optimal resource utilization without manual intervention. For data pipelines that process the same data repeatedly, intermediate result caching can dramatically improve performance by avoiding recomputation. Modern data platforms provide built-in caching mechanisms, while external caching layers like Redis or Memcached can be integrated for custom caching needs.
Scaling Strategies for Growing Data Volumes
Horizontal Scaling Patterns
Microservices Architecture for Data Pipelines applies the principles of microservices to data processing, breaking monolithic pipelines into smaller, independently deployable services that communicate through well-defined APIs or message queues. This approach enables teams to develop, scale, and maintain different parts of the pipeline independently, with each service optimized for its specific function. The challenge lies in managing the increased operational complexity and ensuring data consistency across distributed processing. Service meshes like Istio and Linkerd help manage this complexity by providing service discovery, load balancing, and observability across the microservices ecosystem.
Sharding and Partitioning Strategies distribute data and processing across multiple nodes to handle volumes that exceed the capacity of single machines. Horizontal sharding divides data based on a shard key, with each shard processed independently. Consistent hashing techniques ensure even distribution while minimizing data movement when nodes are added or removed. For time-series data, time-based partitioning naturally aligns with how data is accessed and processed. The key to effective sharding is choosing a partition key that distributes load evenly while aligning with query patterns to minimize cross-node operations.
Auto-scaling and Elastic Resources enable data pipelines to automatically adjust capacity based on workload demands. Cloud platforms provide auto-scaling groups for virtual machines, cluster auto-scaling for Kubernetes, and serverless platforms that scale inherently. Effective auto-scaling requires configuring appropriate metrics (CPU utilization, queue length, custom business metrics) and tuning scaling policies to balance responsiveness against stability. Predictive scaling based on historical patterns can proactively allocate resources before demand spikes, while cost optimization policies ensure that resources are released when no longer needed.
Vertical Scaling and Resource Optimization
Resource Allocation and Management become increasingly important as data pipelines handle larger workloads. Modern orchestration platforms like Kubernetes provide sophisticated resource management through requests and limits that guarantee minimum resources while preventing runaway consumption. Quality of Service (QoS) classes ensure that critical workloads receive priority during resource contention. For memory-intensive processing, techniques like off-heap memory management, efficient serialization formats, and garbage collection tuning help maximize usable memory. The goal is to right-size resource allocation based on actual requirements rather than overprovisioning “to be safe.”
Performance Tuning and Profiling identify bottlenecks and optimization opportunities in data pipelines. Application Performance Monitoring (APM) tools provide code-level visibility into performance characteristics, while distributed tracing follows requests across service boundaries. Profiling tools like Java Flight Recorder, Python cProfile, and Go pprof help identify hot spots in processing logic. The most effective performance tuning follows a systematic approach: establishing baselines, identifying bottlenecks, implementing optimizations, and measuring improvement. Common optimization targets include inefficient algorithms, excessive serialization/deserialization, suboptimal data structures, and unnecessary network transfers.
Cost Optimization and Efficiency have become first-class concerns as cloud spending on data processing grows. Techniques for cost optimization include using spot instances for fault-tolerant workloads, implementing auto-scaling to match resource allocation to actual demand, and choosing appropriate instance types based on workload characteristics. Storage lifecycle policies automatically transition data to cheaper storage tiers as it ages, while data compression and efficient encoding reduce storage requirements. The emerging practice of FinOps brings financial accountability to cloud spending, with cross-functional teams working together to optimize costs while maintaining performance and reliability.
Emerging Trends and Future Directions
AI-Enhanced Data Pipelines
Machine Learning for Pipeline Optimization represents the next frontier in data pipelines automation. ML algorithms can predict optimal resource allocation based on historical patterns, automatically tune configuration parameters for better performance, and identify anomalous behavior that might indicate issues. Reinforcement learning techniques can optimize complex scheduling decisions across multiple pipelines, while natural language processing enables more intuitive interfaces for pipeline management. The integration of ML directly into data pipelines also enables real-time model serving and continuous learning from new data, creating a virtuous cycle where pipelines both consume and produce ML insights.
Automated Data Quality and Anomaly Detection leverage AI to move beyond rule-based quality checks to more sophisticated approaches that learn normal patterns and flag deviations. Unsupervised anomaly detection algorithms can identify unusual data distributions that might indicate quality issues, while time-series forecasting can predict expected data volumes and alert when actual values deviate significantly. Natural language understanding enables automated documentation generation by analyzing pipeline code and data schemas. These AI-enhanced capabilities reduce the manual effort required for data quality management while improving detection of subtle issues that might escape rule-based systems.
Self-Healing and Autonomous Operations represent the ultimate goal of pipeline automation—systems that can detect and resolve issues without human intervention. This includes automatically retrying failed operations with different parameters, dynamically rerouting data flows around problematic components, and even rolling back changes that cause regressions. While fully autonomous data pipelines remain aspirational, we’re seeing increasing automation in areas like resource scaling, performance tuning, and error recovery. The progression is from manual operations to automated assistance to autonomous systems, with each step reducing operational overhead while improving reliability.
Edge Computing and Distributed Processing
Hybrid and Multi-Cloud Data Pipelines have become the reality for most enterprises, requiring data pipelines that can seamlessly operate across different environments. Technologies like Kubernetes provide a consistent abstraction layer across clouds, while data virtualization enables querying data regardless of its physical location. The challenges include managing data gravity (the cost of moving large datasets), ensuring consistent security policies, and maintaining performance across potentially high-latency connections. Emerging standards like the Open Data Federation specification aim to simplify multi-cloud data management by providing common interfaces for discovery, access, and governance.
Edge Computing Integration extends data pipelines beyond centralized cloud environments to include processing at the network edge. This is particularly important for IoT applications, real-time analytics, and scenarios where bandwidth constraints or latency requirements make cloud processing impractical. Edge data pipelines typically involve filtering and aggregating data at the edge before transmitting to central systems, with synchronization mechanisms to handle intermittent connectivity. The architecture often involves a hierarchy of processing layers from device to edge gateway to regional hub to central cloud, with each layer performing appropriate transformations.
Streaming-First Architectures reflect the growing importance of real-time data in business decision-making. Modern data pipelines are increasingly designed with streaming as the default, using change data capture to propagate database changes, event sourcing to maintain state as a sequence of events, and stream processing to derive insights in motion. This shift requires rethinking traditional batch-oriented patterns around concepts like eventual consistency, time-varying data, and reprocessing capabilities. The maturing of stream processing frameworks and the standardization of streaming SQL make these architectures more accessible to organizations without specialized streaming expertise.
Conclusion: Building Future-Proof Data Pipelines
The landscape of data pipelines in 2025 is characterized by increasing automation, intelligence, and complexity. The best practices outlined in this guide provide a foundation for building data pipelines that are not just functional today but adaptable to tomorrow’s requirements. The key trends—AI enhancement, edge computing, real-time processing, and decentralized ownership—point toward a future where data pipelines become increasingly autonomous, ubiquitous, and business-critical.
Success in this evolving landscape requires balancing multiple competing concerns: reliability versus agility, performance versus cost, standardization versus flexibility. The organizations that thrive will be those that treat their data pipelines as strategic assets worthy of investment in architecture, tooling, and skills. This means embracing engineering best practices, adopting appropriate levels of automation, and building cross-functional teams that combine data engineering, data science, and domain expertise.
As we look beyond 2025, the evolution of data pipelines will likely continue toward greater abstraction, intelligence, and specialization. The fundamental goal remains unchanged: moving and transforming data to create business value. By mastering the principles and practices outlined in this guide, organizations can build data pipelines that not only meet today’s requirements but also provide a solid foundation for whatever the future brings.