
Introduction: The Collective Intelligence Revolution
In the rapidly evolving landscape of artificial intelligence, Ensemble Learning has emerged as one of the most powerful and consistently effective methodologies for building superior machine learning models. As we navigate through 2025, the significance of Ensemble Learning has only intensified, transforming from a specialized technique into a fundamental approach that underpins many of the most successful AI systems in production today. The core philosophy of Ensemble Learning is elegantly simple yet profoundly powerful: by combining multiple individual models, we can create a collective intelligence that outperforms any single constituent model. This concept mirrors the wisdom-of-crowds phenomenon observed in human decision-making, where diverse perspectives often lead to better outcomes than individual expertise alone.
The mathematical foundation of Ensemble Learning rests on several key principles that explain why this approach consistently delivers superior results. The first principle is the bias-variance trade-off, where individual models often struggle to find the perfect balance between underfitting and overfitting. Through careful combination strategies, Ensemble Learning effectively manages this trade-off, reducing both bias and variance simultaneously. The second principle involves the concept of diversity, where different models make different types of errors, and when combined strategically, these errors tend to cancel out. The third principle concerns the expansion of hypothesis space, where ensembles can represent more complex functions than any single model could capture independently.
The evolution of Ensemble Learning in 2025 reflects several significant trends that have shaped its current implementation. There has been a dramatic increase in the scale and complexity of ensembles, with modern systems routinely combining hundreds or even thousands of base models. The integration of Ensemble Learning with deep learning architectures has created new hybrid approaches that leverage the strengths of both methodologies.
Additionally, the rise of automated machine learning platforms has made sophisticated ensemble techniques accessible to non-experts, while growing computational resources have made it feasible to deploy massive ensembles in production environments. Perhaps most importantly, there’s been a fundamental shift in how we conceptualize model combination, moving beyond simple averaging to sophisticated meta-learning approaches that dynamically adapt to different data regimes and problem characteristics.
The Fundamental Mechanics of Ensemble Learning
Understanding Ensemble Learning requires a deep appreciation of its underlying mechanics and why this approach consistently produces superior results. At its core, Ensemble Learning operates on the principle that multiple weak learners can be combined to create a strong learner. This concept might seem counterintuitive initially—how can combining mediocre models produce excellence? The answer lies in statistical theory, computational mathematics, and the fundamental nature of machine learning itself.
The statistical foundation of Ensemble Learning begins with understanding the relationship between model diversity and ensemble performance. When we combine models that make uncorrelated errors, the law of large numbers suggests that the ensemble’s overall error will decrease as we add more diverse models. This occurs because each model captures different aspects of the underlying pattern in the data, and their collective wisdom provides a more comprehensive understanding than any single perspective.
The key insight is that the models must be diverse—if all models make the same errors, combining them provides no benefit. This diversity can be achieved through various methods, including using different algorithms, training on different data subsets, employing different feature sets, or introducing randomness in the learning process.
From a computational perspective, Ensemble Learning represents a form of parallel exploration through the hypothesis space. Each base model in the ensemble explores a different region of possible solutions, and the combination mechanism synthesizes these explorations into a more robust final hypothesis. This approach is particularly valuable for complex, high-dimensional problems where no single model architecture can adequately capture the full complexity of the underlying relationships. The ensemble effectively creates a committee of experts, each with their own specialization and perspective, who collectively make better decisions than any individual member.
The mathematical elegance of Ensemble Learning becomes apparent when we examine its error decomposition properties. For regression problems, we can express the expected error of an ensemble in terms of the average error of individual models minus the diversity among them. This relationship demonstrates why diversity is so crucial—without it, ensemble learning provides minimal benefit. For classification problems, the situation is more complex but follows similar principles, with ensemble accuracy being determined by the individual accuracies and the correlation between their errors. When model errors are negatively correlated, the ensemble performance can dramatically exceed that of the best individual model.
Practical implementation of Ensemble Learning requires careful consideration of several key factors. The choice of base models must balance diversity with individual competence—there’s little benefit to combining models that are too weak or too similar. The combination strategy must be matched to the problem type and data characteristics, with different approaches working best for different scenarios. Computational efficiency remains a crucial consideration, as ensembles inherently require more resources than single models. However, with modern distributed computing frameworks and optimized algorithms, the computational overhead of Ensemble Learning has become increasingly manageable, even for large-scale applications.
Advanced Bagging Techniques and Implementations
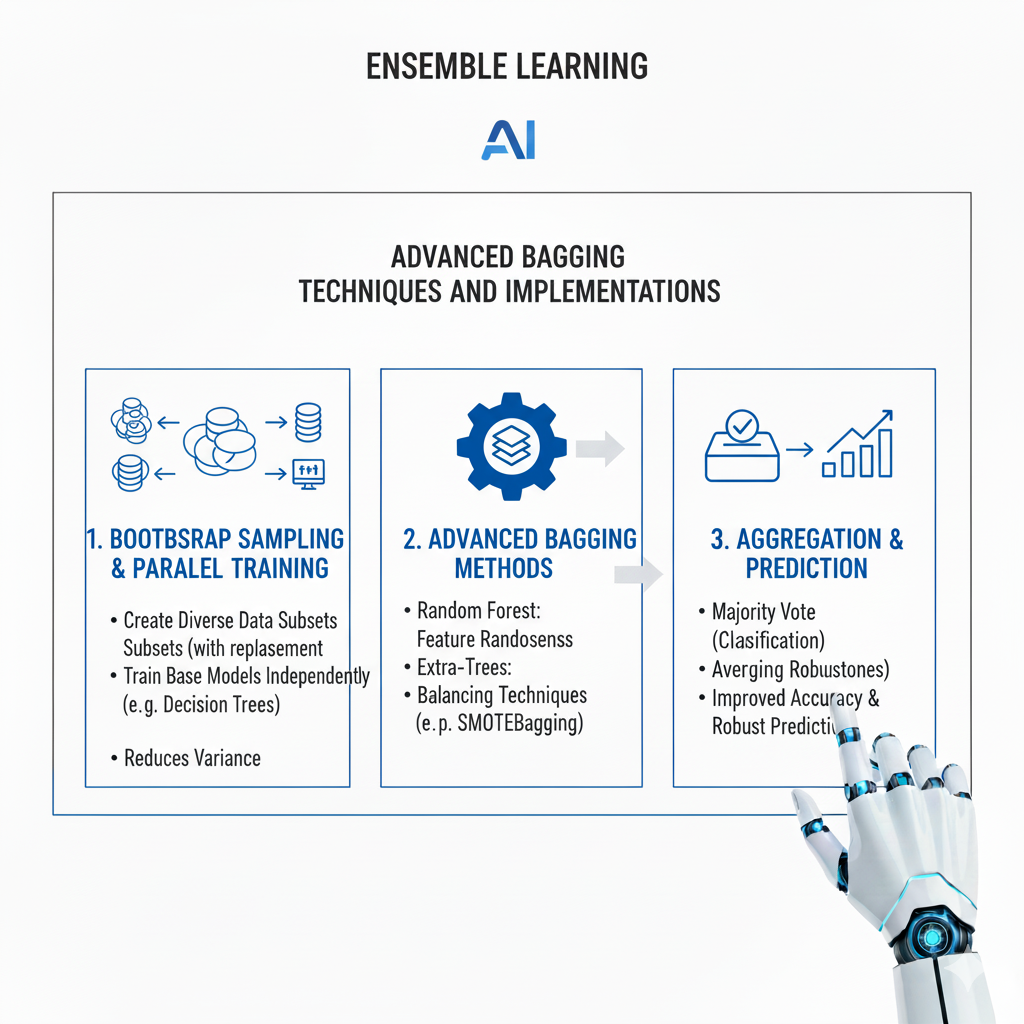
Bagging, which stands for Bootstrap Aggregating, represents one of the most robust and widely applied approaches within Ensemble Learning. The fundamental concept involves creating multiple versions of a training dataset through bootstrap sampling—randomly selecting observations with replacement—and training a separate model on each version. The predictions from these models are then combined, typically through majority voting for classification problems or averaging for regression tasks. This approach might seem straightforward, but its effectiveness stems from deep statistical principles and careful implementation details that have evolved significantly in recent years.
The statistical foundation of bagging lies in its ability to reduce variance without significantly increasing bias. When we train models on different bootstrap samples, each model captures slightly different aspects of the data distribution. Some models might overfit to certain patterns while others underfit, but when combined, these tendencies cancel out, leaving a more stable and reliable prediction. The bootstrap process ensures that each training subset maintains the essential characteristics of the full dataset while introducing meaningful diversity through the sampling variation. This approach is particularly effective for high-variance models like decision trees, where small changes in training data can lead to significantly different tree structures.
Random Forests represent the most famous and extensively developed application of bagging principles within Ensemble Learning. What makes Random Forests particularly powerful is the combination of bagging with random feature selection. At each split in every decision tree, the algorithm considers only a random subset of features, forcing diversity among the trees and preventing them from all focusing on the same strong predictors. This dual randomization—both of training data and features—creates an exceptionally diverse set of base models that collectively provide remarkably robust predictions. The implementation details have become increasingly sophisticated, with modern Random Forests incorporating dynamic feature subspace sizing, adaptive sampling strategies, and intelligent tree depth control.
The evolution of bagging techniques has led to several advanced variations that address specific challenges in modern machine learning. Weighted bagging approaches assign different weights to bootstrap samples based on their characteristics, giving more influence to particularly informative or challenging subsets. Temporal bagging adapts the approach for time-series data, ensuring that the temporal structure is preserved while still creating diverse training sets. Spatial bagging extends the concept to geospatial data, maintaining spatial autocorrelation while introducing controlled variation. These specialized bagging methods demonstrate how the core principles of Ensemble Learning can be adapted to diverse data types and problem domains.
Implementation considerations for bagging ensembles have evolved significantly with advances in computing infrastructure. Parallel processing has become the standard approach, with modern frameworks able to train hundreds of base models simultaneously across distributed computing clusters. Memory optimization techniques allow bagging ensembles to handle datasets that are much larger than available RAM through intelligent streaming and sampling strategies. Model compression methods enable the deployment of large bagging ensembles in resource-constrained environments by approximating the ensemble with a simpler representation while preserving most of its predictive power. These practical advances have made bagging ensembles feasible for applications ranging from edge computing devices to massive cloud-based systems.
Sophisticated Boosting Methodologies and Applications
Boosting represents a fundamentally different approach within Ensemble Learning, one that has produced some of the most powerful predictive models in contemporary machine learning. Unlike bagging, where models are trained independently, boosting involves sequential training where each new model focuses specifically on the examples that previous models found difficult. This iterative refinement process creates a strong learner by gradually correcting the errors of weaker models, with each new model in the sequence specializing in the remaining challenging aspects of the prediction problem. The mathematical elegance of boosting lies in its interpretation as a gradient descent optimization in function space, where we’re sequentially building up an increasingly accurate prediction function.
The theoretical foundation of boosting connects to several deep concepts in statistical learning theory. From one perspective, boosting can be viewed as maximizing the margin—the distance between decision boundaries and training examples—which leads to better generalization. From another perspective, it represents a stagewise additive modeling approach where we’re building a complex model through the combination of many simple components. The success of boosting hinges on the use of weak learners that are only slightly better than random guessing but can be combined to form an arbitrarily accurate strong learner. This combination occurs through careful weighting of each model’s contribution, with more accurate models receiving greater influence in the final ensemble.
Gradient Boosting Machines have emerged as the dominant implementation of boosting principles in modern Ensemble Learning. The key innovation in gradient boosting is framing the sequential learning process as optimizing a loss function through gradient descent. At each iteration, we train a new model to predict the negative gradient of the loss function—essentially learning to correct the current ensemble’s errors. This generalized framework can be applied to any differentiable loss function, making it applicable to regression, classification, ranking, and other specialized tasks. Modern implementations like XGBoost, LightGBM, and CatBoost have refined this core idea with numerous optimizations including efficient histogram-based splitting, sophisticated handling of categorical variables, and advanced regularization techniques.
The practical application of boosting requires careful attention to several hyperparameters and training strategies. The learning rate controls how aggressively each new model adjusts the ensemble’s predictions, with smaller values typically leading to better generalization but requiring more iterations. The depth of base models balances complexity and overfitting, with shallower trees creating more robust ensembles while deeper trees can capture more complex patterns. Early stopping based on validation performance prevents overfitting by terminating the sequential training when additional iterations no longer improve performance on held-out data. These implementation details, while seemingly technical, often make the difference between a mediocre boosting model and an exceptional one.
Recent advances in boosting methodology have addressed several longstanding challenges in Ensemble Learning. Fairness-aware boosting incorporates constraints to ensure that models don’t develop biased behavior toward protected groups. Multivariate boosting extends the approach to problems with multiple correlated outputs. Online boosting enables the technique to work with streaming data where the entire dataset isn’t available upfront. Interpretable boosting variants maintain the power of the approach while providing clearer insights into how predictions are made. These developments demonstrate how boosting continues to evolve, incorporating new requirements and adapting to emerging challenges in the field of machine learning.
Stacking and Meta-Learning Strategies
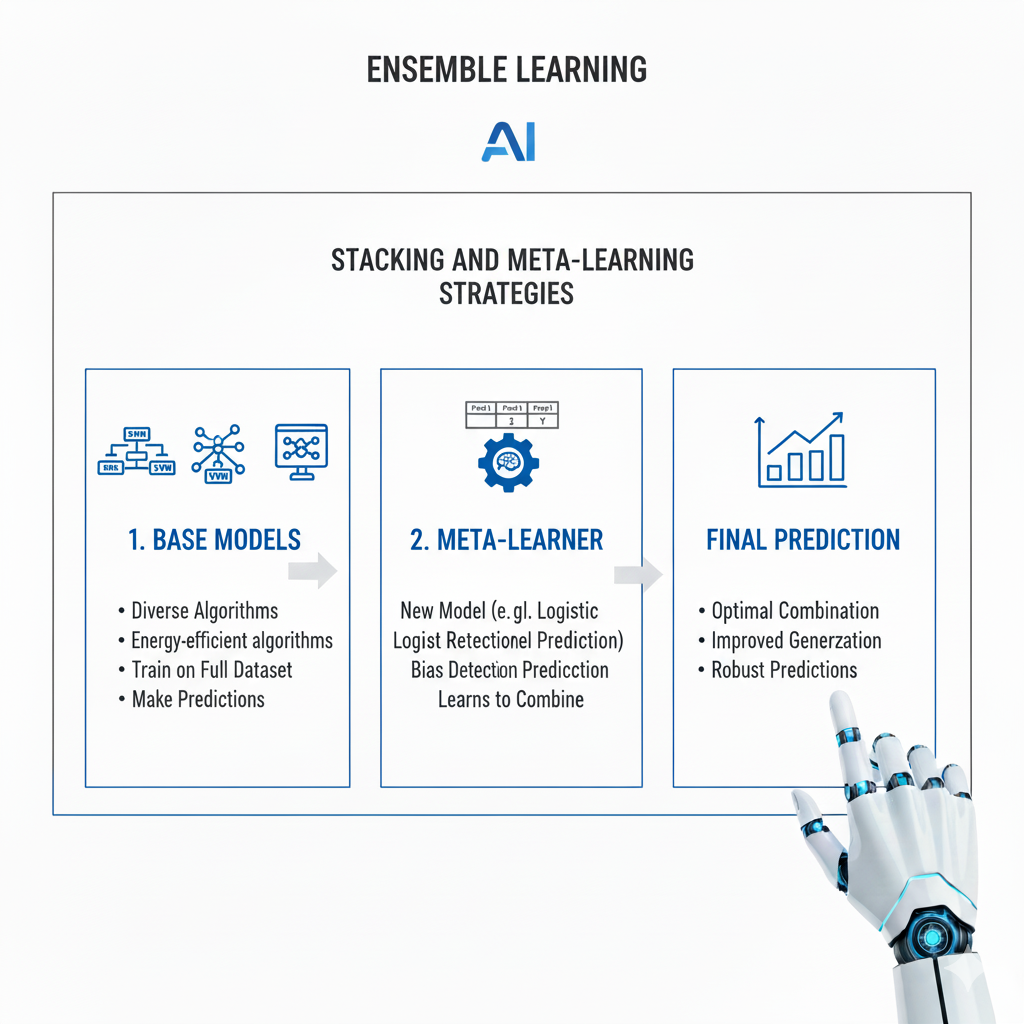
Stacking, also known as stacked generalization, represents the most sophisticated approach within Ensemble Learning, creating a meta-model that learns how to best combine the predictions of multiple base models. Unlike bagging and boosting, which use predetermined combination strategies, stacking learns the combination mechanism from the data itself. This approach recognizes that different models may perform better on different subsets of the feature space or under different conditions, and a smart combination should leverage these complementary strengths. The implementation involves training multiple diverse base models, then using their predictions as features for a meta-model that learns the optimal weighting scheme.
The theoretical justification for stacking comes from the concept of model selection and combination uncertainty. In traditional machine learning, we typically select a single best model based on validation performance, but this discards valuable information from other models that might perform well on certain types of examples. Stacking preserves this information and learns how to leverage it optimally. The meta-model essentially learns the regions of the input space where each base model is most reliable, creating a dynamic combination that adapts to the characteristics of each specific prediction instance. This approach can be viewed as a form of learned voting where the weights aren’t fixed but depend on the input being predicted.
Successful implementation of stacking requires careful attention to preventing overfitting at the meta-learning level. The standard approach involves using out-of-fold predictions for training the meta-model—that is, for each training example, we use predictions from models that weren’t trained on that specific example. This ensures that the meta-model learns genuine complementary relationships rather than memorizing the training data. Additional regularization at the meta-level, such as using simple linear models or heavily regularized neural networks as meta-models, helps prevent the stacking process from overfitting to the base models’ predictions. The diversity of base models remains crucial, as stacking cannot create value from highly correlated predictions.
Advanced stacking architectures have evolved to address complex real-world scenarios. Multi-level stacking creates hierarchies of meta-models, where each level learns to combine the predictions from the level below. This approach can capture increasingly sophisticated combination strategies but requires substantial data and computational resources. Feature-weighted stacking incorporates original features along with model predictions as inputs to the meta-model, allowing it to learn when to trust different models based on input characteristics. Dynamic stacking adapts the combination strategy based on estimated uncertainty or other quality indicators from the base models. These advanced approaches represent the cutting edge of Ensemble Learning, pushing the boundaries of how multiple models can be intelligently combined.
The practical applications of stacking have expanded significantly with improvements in automated machine learning systems. Modern AutoML platforms routinely use stacking as their final ensemble method, automatically testing numerous base models and learning optimal combination strategies. Cross-domain stacking combines models trained on different feature sets or even different data modalities, enabling ensembles that leverage diverse information sources. Online stacking adapts the approach to streaming data environments, continuously updating both base models and the meta-model as new data arrives. These practical advances have made stacking accessible beyond research contexts, enabling organizations to leverage this powerful Ensemble Learning technique in production systems.
Emerging Trends and Future Directions in Ensemble Learning
As we look toward the future of Ensemble Learning, several exciting trends are shaping its continued evolution and expanding its applications. The integration of Ensemble Learning with deep learning represents one of the most promising directions, combining the representational power of deep neural networks with the robustness and calibration benefits of ensemble methods. Deep ensembles, which involve training multiple neural networks with different random initializations and combining their predictions, have shown remarkable improvements in uncertainty quantification and out-of-distribution detection. More sophisticated approaches involve ensembles of specialized networks, where each network focuses on different aspects of complex data, such as different frequency components in signals or different semantic concepts in images.
The democratization of Ensemble Learning through automated machine learning platforms has made these powerful techniques accessible to a much broader audience. Modern AutoML systems automatically explore vast spaces of possible ensemble configurations, testing different combinations of base models, hyperparameters, and combination strategies. These systems use sophisticated search algorithms and performance prediction models to efficiently identify high-performing ensembles without requiring manual experimentation. The result is that organizations without deep machine learning expertise can now leverage state-of-the-art ensemble methods, significantly lowering the barrier to deploying highly accurate predictive models.
Computational efficiency remains a focus of ongoing research and development in Ensemble Learning. While ensembles traditionally required significantly more computation than single models, recent advances have dramatically improved their efficiency. Knowledge distillation techniques train a single model to mimic the behavior of a complex ensemble, preserving much of the performance benefit with far lower computational requirements at inference time. Selective ensemble methods identify small subsets of models that provide nearly the same performance as the full ensemble, reducing both memory and computation needs. Dynamic ensemble selection approaches choose different subsets of models for different inputs, applying full ensemble power only where it’s most needed.
The theoretical understanding of Ensemble Learning continues to deepen, with new insights emerging from statistical learning theory, optimization theory, and computational complexity analysis. Recent work has provided tighter generalization bounds for various ensemble methods, helping practitioners better understand the relationship between ensemble complexity and expected performance. The study of ensemble diversity has evolved beyond simple correlation measures to more nuanced understandings of how different types of diversity contribute to ensemble performance. Connections to other fields, such as distributed computing and multi-agent systems, have provided fresh perspectives on how independent learners can be effectively combined.
Looking forward, Ensemble Learning is poised to play a crucial role in addressing several emerging challenges in artificial intelligence. For safe and reliable AI systems, ensembles provide natural mechanisms for uncertainty quantification and robustness verification. In federated learning environments, ensembles offer elegant solutions for combining models trained on distributed data while preserving privacy. For resource-constrained applications, efficient ensemble methods enable sophisticated AI capabilities on edge devices. The fundamental principles of Ensemble Learning—combining multiple perspectives to achieve better outcomes—will continue to inspire new methodologies and applications, ensuring its enduring relevance in the evolving landscape of artificial intelligence.
Conclusion: The Ensemble Mindset for Advanced Machine Learning
The journey through modern Ensemble Learning reveals a field that has matured from a collection of clever tricks into a comprehensive framework for building robust, accurate, and reliable machine learning systems. The fundamental insight—that multiple models can achieve what single models cannot—has proven remarkably durable across decades of machine learning research and countless practical applications. As we’ve seen, this approach encompasses diverse methodologies including bagging, boosting, and stacking, each with its own characteristics, strengths, and optimal application domains.
What distinguishes contemporary Ensemble Learning is not just the sophistication of its algorithms but the depth of understanding about why and how these methods work. The statistical foundations explaining variance reduction, bias correction, and error cancellation provide a solid theoretical basis for what might otherwise seem like magical improvements. The computational frameworks supporting large-scale ensemble training and deployment have made these techniques practical for real-world applications. The methodological innovations continue to expand the boundaries of what’s possible, incorporating new data types, addressing new challenges, and leveraging new computing paradigms.
The most successful practitioners of Ensemble Learning have embraced what might be called an “ensemble mindset”—a way of thinking about machine learning problems that naturally considers multiple approaches and their intelligent combination. This mindset recognizes that model development shouldn’t be about finding the single best algorithm but about building a coordinated team of models that work together effectively. It understands that diversity in modeling approaches is not a compromise but a strength, and that combination strategies require the same careful design as the individual models themselves.
As artificial intelligence continues to evolve and permeate every aspect of society, the principles of Ensemble Learning will become increasingly important. The need for reliable, robust, and well-calibrated predictions grows as AI systems take on more critical roles in healthcare, finance, transportation, and other high-stakes domains. Ensemble Learning provides essential tools for meeting these demands, offering pathways to better performance without requiring fundamental breakthroughs in base learning algorithms. The future will likely see ensembles not just of machine learning models but of entire AI systems, combining different capabilities and knowledge sources to create artificial intelligence that is truly greater than the sum of its parts.
Mastering Ensemble Learning in 2025 means understanding not just the how but the why—the theoretical principles, practical considerations, and emerging trends that shape this powerful approach. It requires balancing sophistication with practicality, knowing when a simple ensemble will suffice and when a complex stacked approach is warranted. Most importantly, it means recognizing that in machine learning, as in many other domains, collaboration and combination often outperform solitary excellence. By embracing this collective intelligence paradigm, data scientists and machine learning engineers can build AI systems that are not just smarter individually but wiser collectively.