
Master the core architectures powering modern technology with this guide to 8 essential AI models you need to know in 2025. Explore Transformers, Diffusion models, GNNs, and more – understand how each AI model works and its real-world applications from ChatGPT to medical imaging.
Introduction: The New Foundational Literacy
We are no longer merely in the age of digital transformation; we have entered the age of cognitive integration. As we progress through 2025, artificial intelligence has shed its speculative skin to become the operational bedrock of industry, a catalyst for unprecedented creativity, and an invisible, intelligent layer woven into the fabric of daily life. This seismic shift is not powered by a singular, monolithic intelligence, but by a diverse and specialized ecosystem of architectural paradigms. At the heart of each breakthrough—from conversational chatbots that understand nuance to systems that discover new drugs—lies a specific ai model, a unique blueprint for machine cognition.
An ai model is far more than a cluster of algorithms or lines of code. It is a carefully engineered framework, a distinct “cognitive style” that dictates how a system processes information, learns from data, and generates insights or outputs. Understanding these blueprints has transcended the realm of computer science to become a fundamental form of literacy. For the professional, it enables the strategic selection and application of AI tools. For the creator, it unlocks new mediums and methods of expression. For the global citizen, it provides the critical lens required to navigate an increasingly automated world, fostering informed discourse on ethics, economics, and society.
This article serves as a deep dive into eight pivotal ai model architectures that are powering the most significant innovations of our time. We will dissect them not just as theoretical constructs, but as practical engines of change, exploring their inner workings, their real-world applications, and the unique problem-solving niche each one occupies. By mastering the concepts behind these models, you gain a map to navigate the present and future of technology.
1. The Transformer Model: The Architect of Context
If one ai model can be credited with defining the current era of AI, it is the Transformer. Originally designed for natural language processing, its influence has become so ubiquitous that it now serves as the foundational engine for everything from advanced reasoning systems to generative art.
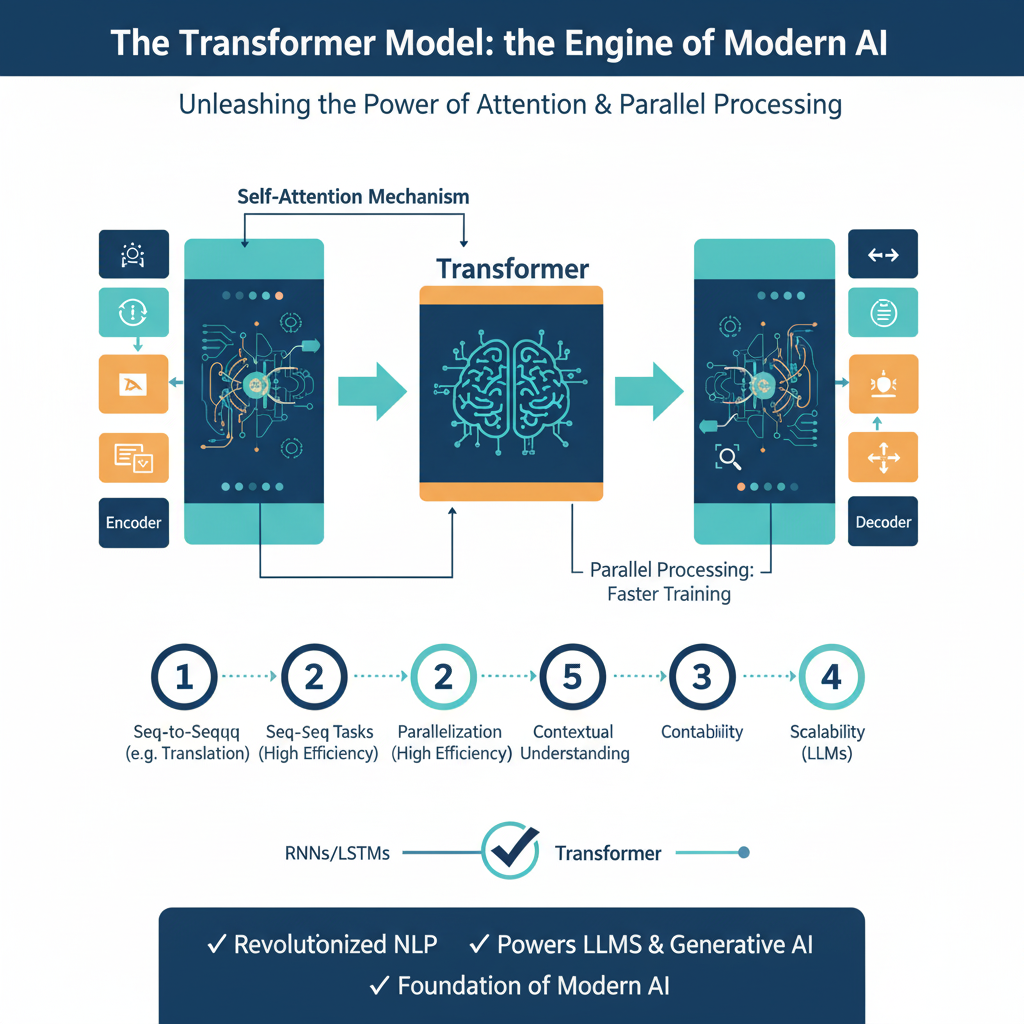
Core Concept: The Self-Attention Revolution
The Transformer’s revolutionary power stems from its “self-attention” mechanism, which fundamentally altered how sequences are processed. Previous models, like Recurrent Neural Networks (RNNs), processed data sequentially—one word after another—which was inherently slow and struggled with long-range dependencies. Self-attention, in contrast, allows this ai model to view an entire sequence simultaneously.
For any given element in a sequence (e.g., a word in a sentence), self-attention computes a weighted score against every other element. This means the representation of the word “it” in the sentence “The cat sat on the mat because it was tired” is dynamically and strongly influenced by “cat,” while in “The code was complex, but the engineer refactored it,” “it” is shaped by “code.” This ability to create context-aware representations in parallel is the Transformer’s superpower ai model,.
Technical Architecture: Encoders, Decoders, and Multi-Head Attention
A standard Transformer employs an encoder-decoder structure. The encoder is a stack of identical layers, each containing a multi-head self-attention mechanism and a feed-forward neural network, with residual connections and layer normalization stabilizing the training process.
“Multi-head” attention allows the ai model to run several self-attention operations in parallel, each focusing on different types of relationships—one head might track grammatical agreement, while another tracks semantic roles. The decoder is similarly structured but includes an additional attention layer that lets it focus on the encoder’s output, making it ideal for sequence-to-sequence tasks like translation. Crucially, the decoder uses masked self-attention to prevent it from peeking at future tokens during training, forcing it to learn autoregressive generation.
Why It’s Indispensable in 2025: The Bedrock of Modern AI
The Transformer is the core ai model behind all Large Language Models (LLMs), including GPT-4, Claude, and Llama. Its influence extends far beyond text. Vision Transformers (ViTs) treat images as sequences of patches, achieving state-of-the-art results in computer vision. Furthermore, it is the central nervous system of multimodal AI, where separate Transformer-based encoders for text, vision, and audio are fused to create systems that can understand and reason across different data types. To understand the current and near-future state of AI is to understand the Transformer.
Primary Applications:
- Powering all modern LLMs and chatbots.
- Machine translation and text summarization.
- Image and video recognition via Vision Transformers (ViTs).
- The core fusion engine for multimodal AI systems.
2. Large Language Models (LLMs): The Conversational Universe
An LLM is a specific, massively scaled type of ai model, almost always based on the Transformer decoder, that is trained to understand, generate, and manipulate human language with remarkable proficiency.

Core Concept: Emergent Intelligence from Prediction
The “intelligence” exhibited by LLMs is an emergent property of a deceptively simple objective: predict the next token (word or sub-word) in a sequence. Trained on a significant fraction of the digital text produced by humanity, the model adjusts its hundreds of billions of parameters to minimize prediction error. To excel at this task, it must implicitly learn not just grammar and vocabulary,
but also world knowledge, logical reasoning, cultural nuance, and even elements of common sense. The resulting ai model is a high-dimensional statistical map of language, where semantically related concepts inhabit similar regions in a vast vector space. This is why LLMs can perform tasks like translation or summarization without explicit training—these abilities emerge from mastering the underlying structure of language.
Technical Architecture: Scale, Sparsity, and Specialization
Modern LLMs have largely adopted a “decoder-only” architecture, as popularized by the GPT series. This design is optimized for the autoregressive generation of text. The key to their power lies in scale and architectural innovations designed to manage it:
- Sparse Mixture-of-Experts (MoE): To manage computational cost, MoE models like Mixtral 8x7B do not activate all their parameters for every input. Instead, a gating network routes each token to a small subset of specialized “expert” networks, dramatically increasing total parameter count (and thus knowledge capacity) without a proportional increase in computation.
- Advanced Positional Encoding: Techniques like Rotary Positional Embedding (RoPE) provide the model with a more robust sense of word order over long contexts than the original Transformer’s sinusoidal embeddings, which is critical for understanding long documents or complex narratives.
Why It’s Indispensable in 2025: The Primary Human-AI Interface
LLMs have evolved from text generators into reasoning engines and agentic systems. They are the core of AI assistants that can plan, write and execute code, and use external tools (calculators, APIs, web browsers). Understanding this ai model is crucial for leveraging its capabilities through prompt engineering and for comprehending its limitations, such as “hallucination”—the generation of plausible but factually incorrect information—which is a direct consequence of its statistical, generative nature.
Primary Applications:
- Chatbots and conversational AI (ChatGPT, Claude).
- Code generation and assistance (GitHub Copilot).
- Content creation, summarization, and knowledge synthesis.
- The brain for autonomous AI agents.
3. Convolutional Neural Networks (CNNs): The Visual Perception Engine
Before the rise of Transformers, the Convolutional Neural Network was, and in many contexts remains, the quintessential ai model for any task involving pixel data, serving as the foundational technology for modern computer vision.
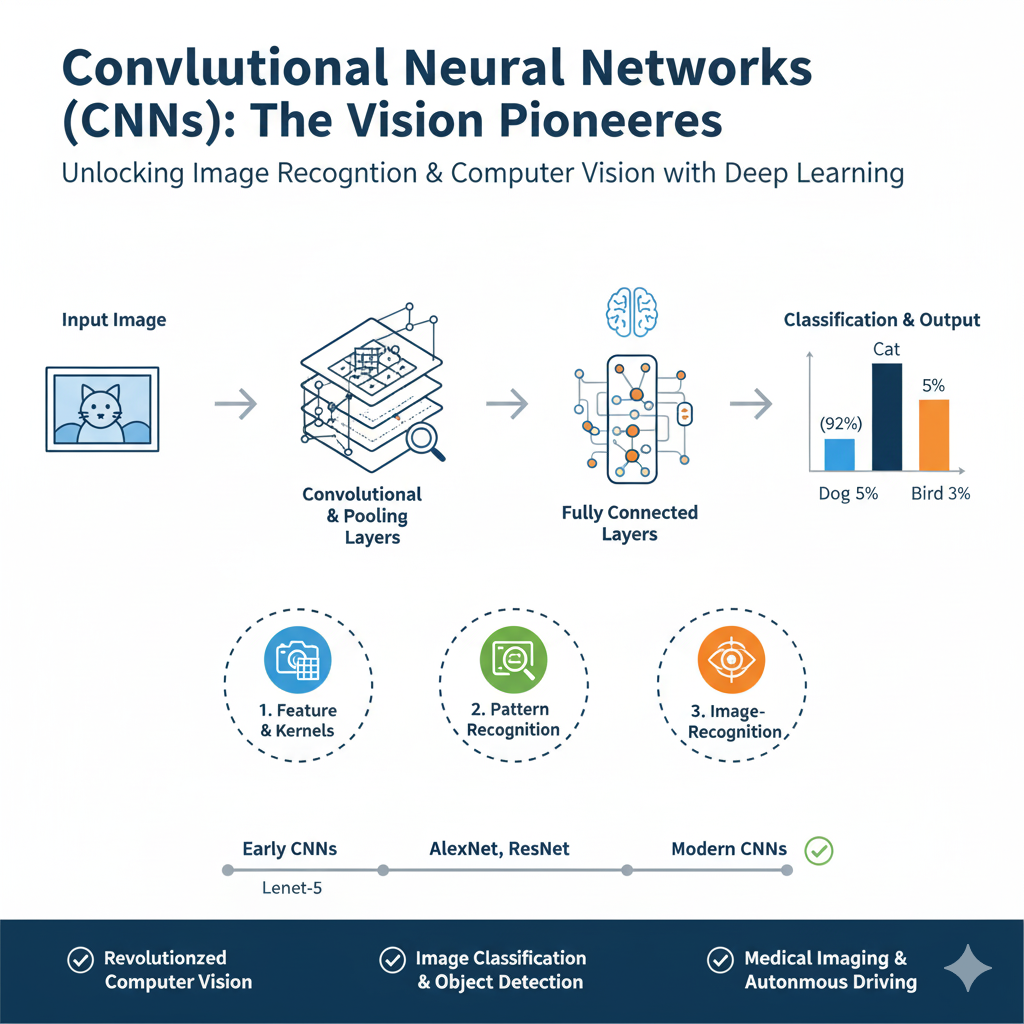
Core Concept: Hierarchical Feature Learning through Filters
The CNN is inspired by the biological visual cortex. Its core operation is the mathematical convolution, where small, learnable filters (kernels) slide across the width and height of an input image. Each filter activates when it detects a specific low-level feature, such as a vertical edge, a horizontal line, or a specific color contrast.
The output is a set of “feature maps.” As these maps are passed through successive layers, the network learns to combine these simple features into increasingly complex constructs—edges form contours, contours form shapes, and shapes form object parts. Interspersed pooling layers (e.g., MaxPooling) progressively reduce the spatial dimensions, providing computational efficiency and, more importantly, making the network invariant to the exact position of a feature, focusing on its presence ai model,.
Technical Architecture: Depth and Residual Learning
Classic CNN architectures like VGG and Inception demonstrated the power of depth. However, truly deep networks were plagued by the “vanishing gradient” problem, where signals would fade during training. The ResNet (Residual Network) ai model solved this with a brilliant innovation: “skip connections” or “residual blocks.” These connections allow the input to bypass one or more layers and be added directly to the output.
This creates a pathway for gradients to flow directly backward, enabling the stable training of networks that are hundreds of layers deep, which was a watershed moment for computer vision.
Why It’s Indispensable in 2025: Unmatched Efficiency for Real-Time Vision
While Vision Transformers are gaining ground, CNNs maintain a stronghold in resource-constrained and real-time applications. Their architecture embodies a powerful “inductive bias” for images—the assumption that pixels are most relevant to their local neighbors—which makes them exceptionally computationally efficient. This ai model is the workhorse for real-time object detection in autonomous vehicles, medical image analysis (e.g., tumor detection in MRI scans), and industrial quality control systems on manufacturing lines, where speed and reliability are paramount.
Primary Applications:
- Real-time image and video recognition.
- Medical image analysis and diagnostics.
- Autonomous vehicle perception systems.
- Facial recognition and biometric security.
4. Diffusion Models: The Generative Alchemists
This ai model has single-handedly catalyzed the generative AI art revolution, powering tools like Stable Diffusion, Midjourney, and DALL-E by mastering the process of creating order from chaos.

Core Concept: Iterative Denoising
Diffusion models learn by a two-step process centered on a Markov chain:
- Forward Process: A training image is progressively corrupted by adding Gaussian noise over a fixed number of steps (e.g., 1000) until it becomes pure, isotropic noise. This is a predetermined process that requires no learning.
- Reverse Process: A neural network (typically a U-Net) is trained to reverse this noising. It takes a noisy image and the current timestep as input and learns to predict the noise that was added. To generate a new image, the process starts with a random noise field and iteratively applies the trained model to “denoise” it over multiple steps, gradually refining the noise into a coherent, high-fidelity image. For text-guided generation, the text prompt is injected into the U-Net via cross-attention layers, steering the denoising toward the desired concept.
Technical Architecture: The U-Net and Guided Synthesis
The U-Net architecture is perfectly suited for this task. It features an encoder that downsamples the image to capture contextual information and a decoder that upsamples to recover spatial detail. The critical “skip connections” between corresponding encoder and decoder layers allow the ai model to preserve high-frequency details from the input noise that would otherwise be lost, enabling the generation of sharp, photorealistic outputs. The guided synthesis, whether by text, class labels, or other modalities, is what makes this ai model so controllable and versatile.
Why It’s Indispensable in 2025: The Standard for Generative Media
Diffusion models are the state-of-the-art ai model for most generative media tasks. Their application has expanded beyond static images to video generation (e.g., OpenAI’s Sora), where the denoising process operates across spatial and temporal dimensions. Furthermore, their principles are being applied in scientific domains like drug discovery, where the “denoising” process starts from a random molecular graph and iteratively refines it into a novel, stable compound with desired properties, showcasing their potential beyond creative fields.
Primary Applications:
- Photorealistic image generation from text prompts.
- Video generation and editing.
- Audio synthesis and music generation.
- 3D asset creation and molecular design.
5. Generative Adversarial Networks (GANs): The Adversarial Artisans
Though partly superseded by Diffusion models for general image synthesis, the GAN remains a historically pivotal and conceptually brilliant ai model that introduced a powerful new framework for generation.\
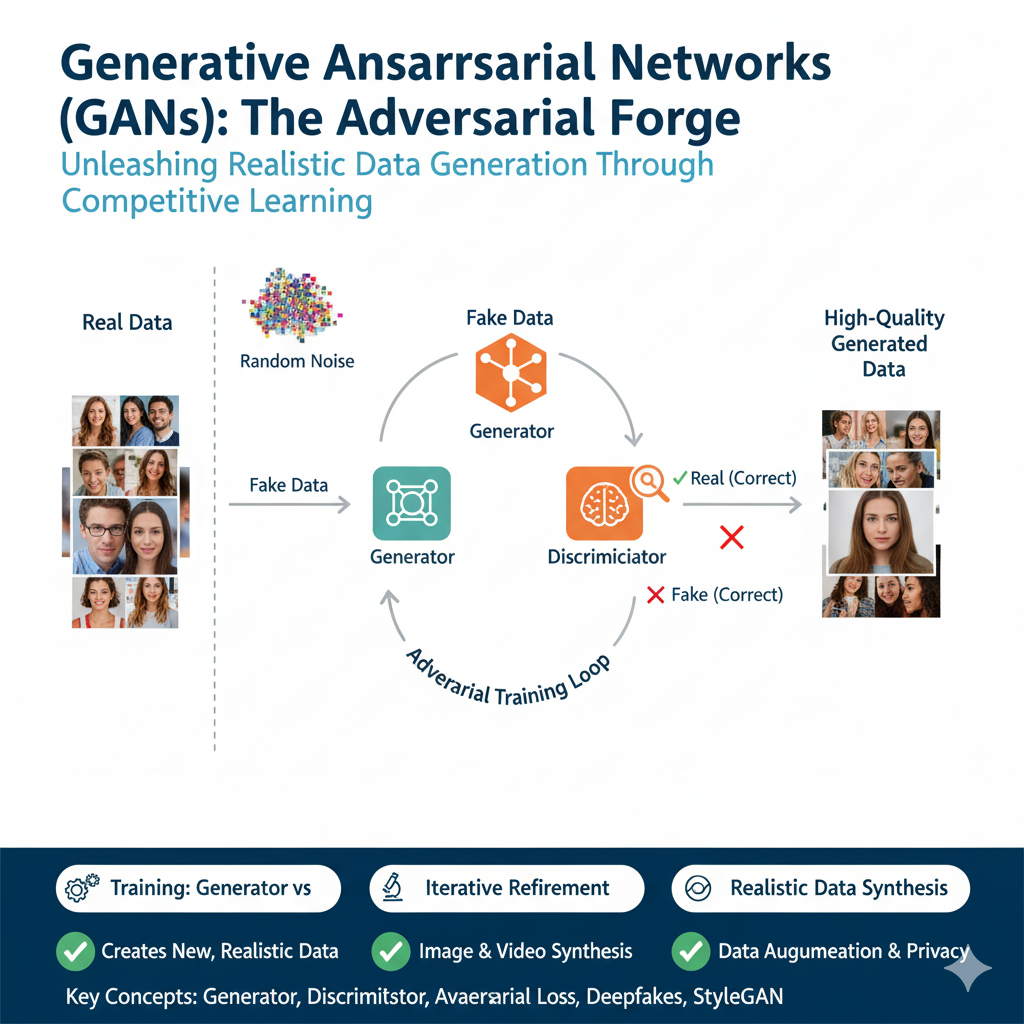
Core Concept: The Two-Player Game
A GAN consists of two neural networks locked in an adversarial contest:
- The Generator creates synthetic data from a random noise vector.
- The Discriminator attempts to distinguish the generator’s fakes from real training data.
The two networks are trained simultaneously in a minimax game. The discriminator is trained to maximize its classification accuracy, while the generator is trained to minimize the discriminator’s ability to spot its fakes. - This creates a dynamic feedback loop: as the discriminator gets better, the generator is forced to produce more convincing outputs. In an ideal equilibrium, the generator produces data indistinguishable from reality, and the discriminator is left guessing at a 50% accuracy rate ai model,.
Technical Architecture: Achieving Stability and Control
Early GANs were notoriously difficult to train, suffering from “mode collapse” (where the generator produces limited varieties of output). The Wasserstein GAN with Gradient Penalty (WGAN-GP) was a major advance, using a more stable loss function based on the Earth-Mover’s distance.
StyleGAN took quality and control to a new level by designing a generator that first learns coarse features (e.g., face shape) and then progressively refines finer details (e.g., hair, eyes) through injected “style” vectors, allowing for unprecedented manipulation of the generated output’s attributes.
Why It’s Indispensable in 2025: Niche Dominance and Historical Foundation
While no longer the dominant ai model for standard image generation, GANs still excel in applications requiring extreme fidelity and precise image-to-image translation. They are state-of-the-art for tasks like generating photorealistic human faces, creating “deepfakes,” and performing style transfer. Furthermore, understanding the adversarial training paradigm provides deep insights into other areas of machine learning, including AI safety and robustness testing. They laid the essential groundwork for the generative AI era.
Primary Applications:
- High-fidelity image generation of human faces.
- Data augmentation for training other models.
- Image-to-image translation (e.g., turning sketches into photos, day to night).
- Style transfer and deepfake creation.
6. Recurrent Neural Networks (RNNs) & LSTMs: The Sequential Memory Keepers
Before the Transformer’s ascendancy, Recurrent Neural Networks and their more powerful variant, Long Short-Term Memory (LSTM) networks, were the primary ai model for handling sequential data like time series and text.
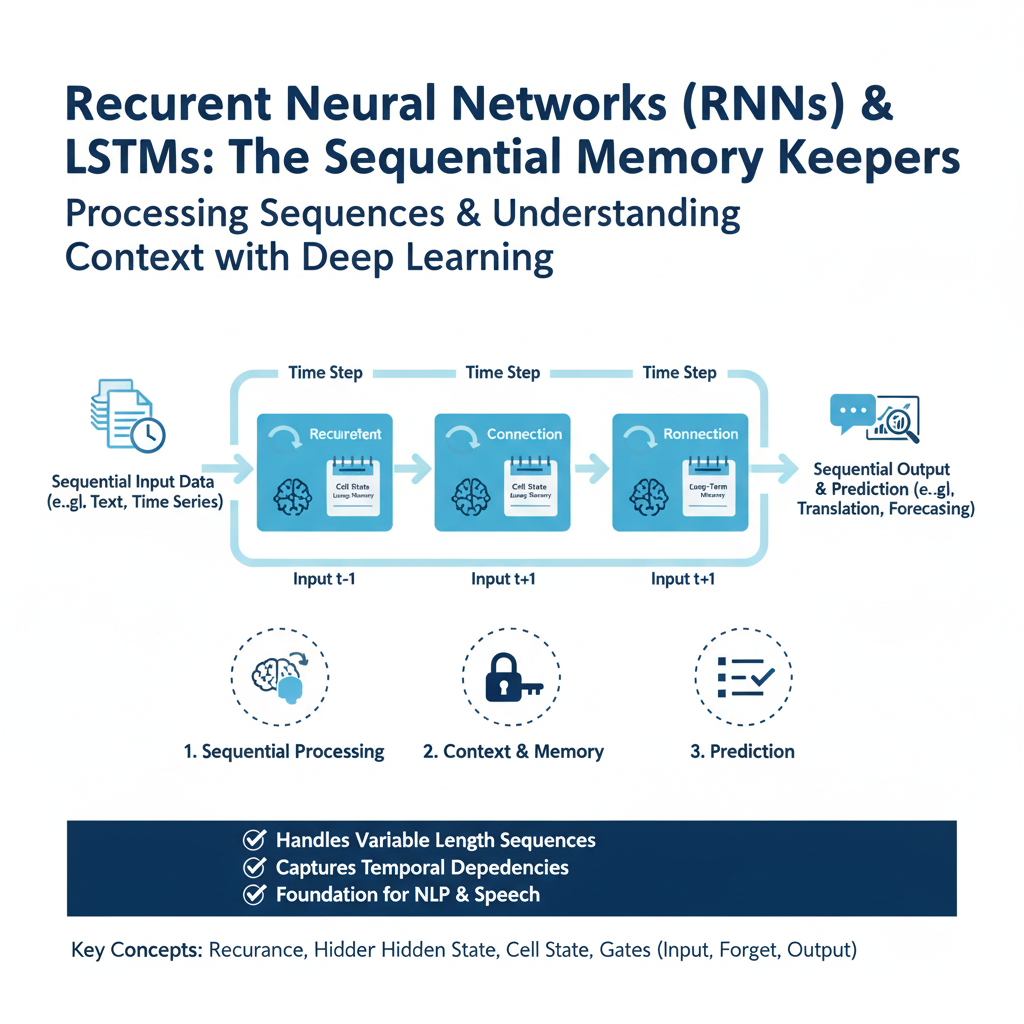
Core Concept: Networks with Internal State
The core innovation of RNNs is their recurrent connection, which loops the network’s hidden state from one timestep as an input to the next. This creates an “internal memory” that allows information to persist, making them theoretically well-suited for sequences where context from the past is crucial. However,
simple RNNs suffer from the vanishing/exploding gradient problem during backpropagation through time (BPTT), making it impossible to learn long-range dependencies. The LSTM ai model was designed explicitly to solve this. It introduces a “cell state” (C_t) that acts as a conveyor belt for information, regulated by three learned gates:
- Forget Gate: Decides what information to remove from the cell state.
- Input Gate: Decides what new information to store in the cell state.
- Output Gate: Decides what part of the cell state to output as the hidden state.
This gating mechanism allows LSTMs to selectively remember or forget information over very long sequences, making them effective for tasks where context matters.
Technical Architecture: The Gated Recurrent Unit
A popular and slightly simplified variant of the LSTM is the Gated Recurrent Unit (GRU). It combines the forget and input gates into a single “update gate” and merges the cell state and hidden state, resulting in a more streamlined ai model that is often faster to train while still performing comparably to an LSTM on many tasks.
Why It’s Indispensable in 2025: The Go-To for Streaming Data
In the era of the Transformer, RNNs/LSTMs/GRUs have found a vital niche in low-latency, continuous streaming applications. Transformers, with their self-attention mechanism, are computationally intensive and often process fixed-length sequences. RNNs, however, process data one step at a time with a fixed, small computational cost per step.
This makes them ideal for real-time tasks like sensor data forecasting in IoT networks, live speech-to-text on edge devices, and high-frequency algorithmic trading, where low latency is more critical than capturing extremely long-range context ai model,.
Primary Applications:
- Real-time time-series forecasting and anomaly detection.
- Speech recognition on edge devices.
- Financial market prediction.
- Classic machine translation (pre-Transformer).
7. Graph Neural Networks (GNNs): The Relational Reasoning Engines
As AI tackles more complex, interconnected problems, the Graph Neural Network has emerged as the critical ai model for understanding data defined by its relationships.
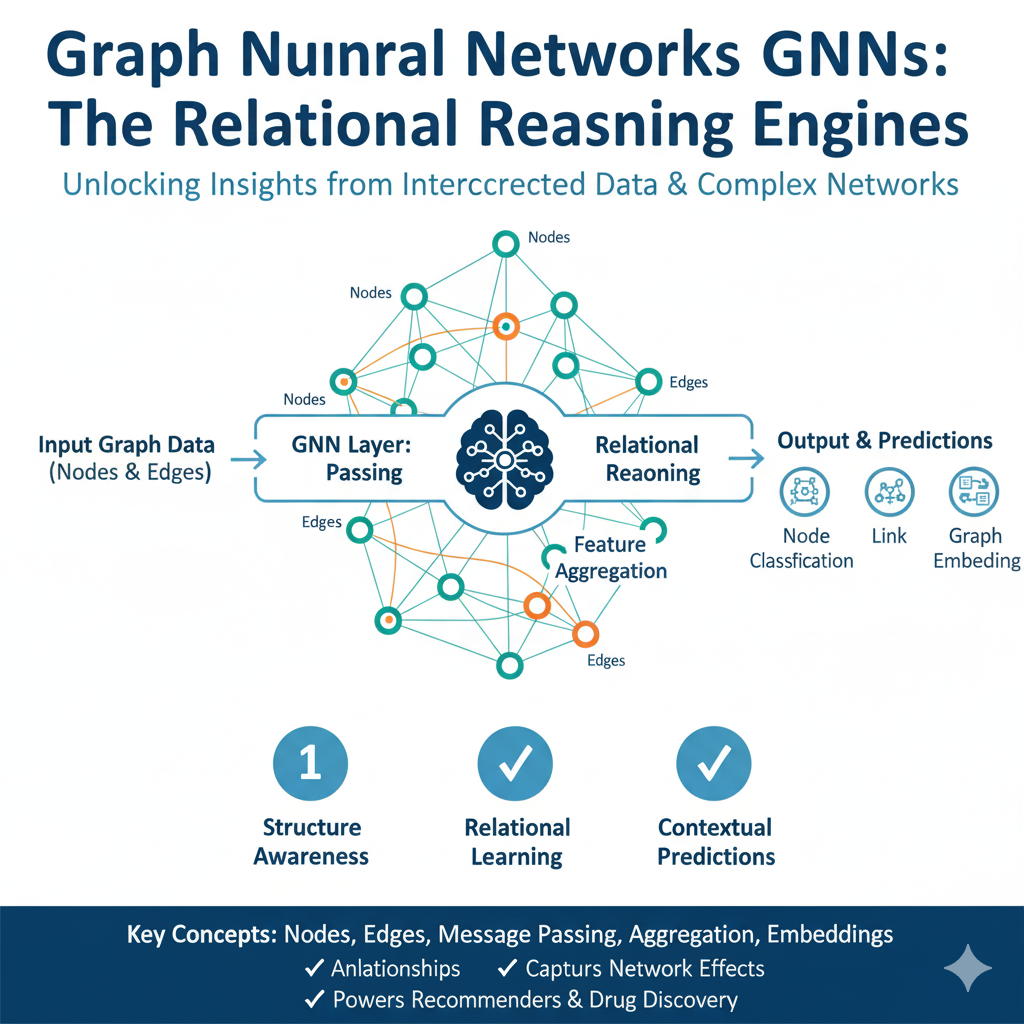
Core Concept: Learning from Structure via Message Passing
GNNs operate directly on graph data structures—networks of nodes (entities) connected by edges (relationships). The core operational framework is message passing. In each layer, every node computes a new representation by:
- Aggregating the features (or “messages”) from its neighboring nodes.
- Updating its own state by combining the aggregated neighborhood information with its previous state.
Afterklayers of message passing, each node’s representation encapsulates structural information about itsk-hop neighborhood. This allows the ai model to learn not just from the features of individual entities, but from the entire topology of the network they form.
Technical Architecture: Variants for Different Tasks
The GNN family includes several specialized architectures:
- Graph Convolutional Networks (GCNs): Perform a normalized aggregation of neighbor features, akin to a convolution operation on a graph.
- Graph Attention Networks (GATs): Use an attention mechanism to assign different importance weights to each neighbor, allowing the model to focus on more critical connections.
- GraphSAGE: An inductive framework that generates embeddings for unseen nodes by sampling and aggregating from their local neighborhood, making it scalable to massive, evolving graphs.
Why It’s Indispensable in 2025: Modeling Complex Systems
GNNs are fundamental to scientific discovery and complex systems analysis. In drug discovery, molecules are natively represented as graphs (atoms are nodes, bonds are edges), and GNNs can predict a molecule’s properties or generate new candidate drugs. They are the engine behind modern recommendation systems, which model user-item interactions as a graph.
They are also crucial for fraud detection, where they can identify suspicious patterns in complex transaction networks. As more real-world data is recognized as interconnected, this ai model class is becoming one of the most rapidly growing and impactful areas of AI model research.
Primary Applications:
- Drug discovery and molecular property prediction.
- Social network analysis and recommendation engines.
- Fraud detection in financial networks.
- Supply chain optimization and power grid management.
Conclusion: A Symphony of Specialized Intelligence
The AI landscape of 2025 is not a monolith dominated by a single form of intelligence. Instead, it is a rich and dynamic ecosystem where specialized ai model architectures work in concert, each a master of its own domain. The Convolutional Neural Network remains a robust and efficient perceiver of visual patterns.
The Transformer has established itself as the dominant architect of language and context. The Graph Neural Network is unlocking the power of relational reasoning in complex systems. Meanwhile, generative models like Diffusion networks are creating new realities, and Multimodal models are stitching our sensory world into a unified whole.
To understand these eight models is to acquire a mental map of modern artificial intelligence. It empowers you to discern the technology powering the tools you use, make strategic decisions about their application, and critically evaluate their societal impact. More than that, it allows you to appreciate the breathtaking symphony of specialized “minds” that are, collectively, shaping our future. As these models continue to evolve and converge, this foundational knowledge will be your most valuable asset for navigating the promises and challenges of the cognitive age.